The article goal is to give those people who are new to Big Data Hadoop. This article does not prepare you for Hadoop programming, but you will acquire a sound knowledge of the fundamentals of Hadoop and its core components. You will also find out why people started using Hadoop and why it just became so common in the short span of time.
The way Hadoop handles big data is simply amazing. This is why the organizations which deal with large data like to use hadoop systems.Some of Hadoop's popular users are Yahoo, Amazon, eBay, Twitter, Google, IBM, and so on. Currently, Hadoop has made a prominent reputation for the big data-driven industries and manages increasingly sensitive information that could be used to provide more insights. You can use it for all business sectors, such as Banking, Telecommunications, Retail, Internet, Business, etc. Hadoop's applications don't stop here but it definitely gives you an idea of Hadoop's development and career prospects in reputable organizations,More info go through big data online training.
Hadoop
Hadoop Big Data is an open-source Apache application developed for working with big data. Hadoop's main objective is data collection from various distributed sources, data processing, and resource management to handle such data files.
People typically get confused between Hadoop terminology and big data. Such words are used interchangeably by few people but should not be. Hadoop is simply a platform designed to work with Big Data. With HDFS, Hadoop also gets access to multiple file systems, as the organizations allow.
Misconceptions about Hadoop:
Hadoop is not Big Data ,people are generally confused with the words Hadoop and big data.Hadoop is a platform to use big data and both are not the same. You should not make the mistake of confusing Hadoop with big data.
Some people regard Hadoop as an operating system or set of packaged software apps. But ,it is not an operating system or a set of packaged software apps.
Hadoop is not a brand, but an open source platform, registered brands can use on basis of their requirements.
Detailed discussion on Hadoop modules or core elements to give you valuable insights into the Hadoop architecture and Hadoop distributed file system.
Hadoop modules:
The hadoop modules are as follows.
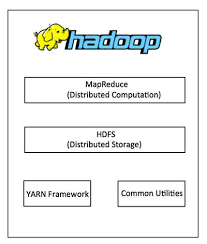
Hadoop YARN
YARN resource navigator helps manage resources and plan research through various clusters that store the data. Key elements of the application include Node Manager, Resource Manager, Server Administrator, and so on.
The Resource Manager assigns resources to the project. The Node Manager handles these resources on various machines such as CPU, network, or memory etc. For the other two elements, the "Application Manager" acts as a library, and sits between the two. This helps in the management of capital, so that you can execute tasks successfully.
Hadoop MapReduce
MapReduce operates like Hadoop YARN designed to process large sets of data. This method allows concurrent handling on distributed servers. MapReduce transforms large blocks into smaller data sets which are called in Hadoop as Tuples before actual data is processed.
Compared to larger data files tuples are easy to grasp and operate on. Once MapReduce completes the processing of data then work is passed on to the HDFS module to process the final output. In short, MapReduce's aim is to break large data files into smaller chunks, which are simple to manage and process.
The word MAP here refers to Place, Jobs, and Functions. The "Chart" method is aimed at encoding data into key-value pairs and assigning it to specific nodes. Upon introducing this "reduce" feature, you may find large data files reduced into smaller chunks or "tuples." One of the important components of the MapReduce feature is JobTracker, and you can find this in hdfs in the next half of the article.
This module contains a collection of utilities that support three other modules. Many of the other elements of the Hadoop ecosystem are Oozie, Sqoop, Spark, Hive, or Pig etc.
Hadoop Popular:
This module contains a collection of utilities that support additional modules. Some of the other components of the Hadoop ecosystem are Oozie, Sqoop, Fire, Hive, or Pig etc.
Hadoop distributed file system(hdfs)
This core module offers access to big data distributed through several commodity server clusters. Through HDFS, Hadoop often gets access to multiple file systems, and as of now it can operate with almost any file system. This is the primary requirement of organizations, so Hadoop Framework has become so common in a shorter time span. HDFS core module functionality makes it the heart of the Hadoop framework.
HDFS keeps track of how files are distributed or stored in clusters. Data is further broken down into blocks, and blocks need wise access to prevent redundancy.
It has a distributed file system known as HDFS, and this HDFS breaks files into blocks and sends them in the form of large clusters across different nodes. The device also works in the event of a node failure, and data transmission occurs between the nodes facilitated by HDFS.The components of HDFS are as follows.
NameNode
The HDFS cluster operates as a single master server.
Since it is a single node, it will become the cause for the failure of one stage.
It handles namespace of the file system by performing an operation such as opening, renaming, and closing the files.
It simplifies the Hadoop Architecture.
DataNode
The HDFS cluster contains many DataNodes.
Each DataNode is composed of several data blocks.
Such blocks of data are used to store data.
It is DataNode's responsibility to read and write requests from clients within the file system.
Upon instruction from the NameNode it performs block formation, deletion and replication.
Job Tracker
The function of Job Tracker is to accept client MapReduce jobs and use NameNode to process the data.
In return, the job tracker is given metadata by NameNode.
Project Tracker
The Project tracker(job tracker) functions as a slave server.
It receives project tracker tasks and code, and applies the code to the file. You may also call this method a Mapper.
MapReduce Layer
The MapReduce comes into being when the MapReduce job is sent to Job Tracker by the client application. The Job Tracker sends the request to the respective Project Trackers in response. TaskTracker often fails, or time out. A part of the job is rescheduled in such a situation.
Advantages of HDFS:
It is cheap, unchangeable in nature, efficiently stores data, ability to withstand faults, flexible, organized blocking, can process large volumes of data at the same time and much more.
HDFS disadvantages:
The main drawback is that it isn't ideal for small amounts of data. It also has issues surrounding potential stability, in essence restrictive and rough.
Software packages with Hadoop support:
Hadoop also supports a range of following software packages
Apache Flumes,
Apache Oozie,
Apache HBase,
Apache Sqoop,
Apache Spark,
Apache Storm,
Apache Pig,
Apache Hive,
Apache Phoenix, and
Cloudera Impala software packages.
Conclusion:
I hope you have enjoyed reading the article. If you have been reading through this article, you might be interested in checking out the specifics on Hadoop training programs with expert advice. If you also wanted to start your career as a Hadoop professional then immediately join a OnlineItGuru big data hadoop training program.
No comments:
Post a Comment