Distributed data processing refers to the distribution of computer networks
across different locations where computer systems interconnected & share data.
Apache Spark is an open-source general distributed data processing engine with
capacity to handle heavy volumes of data.
Moreover, it supports different types of resources or cluster managers. Such as
Standalone, Kubernetes, Apache Mesos & Apache Hadoop YARN (Yet Another
Resource Negotiator).
It includes an extensive set of libraries and APIs and supports different
programming languages like Java, Scala, Python, R, etc. Moreover, its flexibility
makes it suitable for a wide range of use cases.
Apache Spark is also useful with distributed data stores like MapR XD, Hadoop’s
HDFS, etc. And with popular NoSQL databases like MapR Database, Apache
HBase, and MongoDB. And it also used with distributed messaging stores like
MapR Event Store and Apache Kafka.
To learn big data course visit OnlineITGuru's big data and hadoop online training Blog
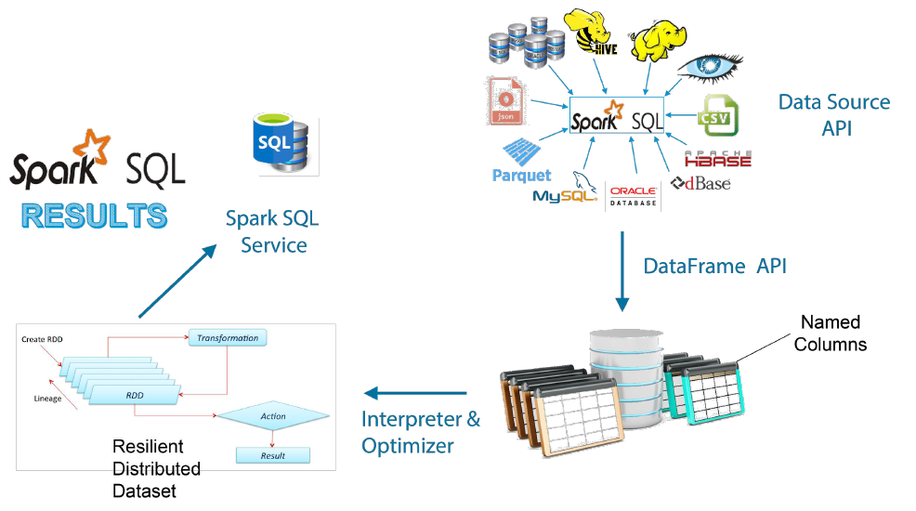
Spark distributed computing example
It includes the concept of distributed datasets that contains the objects Python or
Java. There are different types of Spark APIs available on the top of the Spark that
are the building blocks of Spark API. These are RDD API, DataFrame API & the
Machine Learning API.
Besides, these APIs also provides the way to conduct DDP operations under Spark.
RDD (Resilient Distributed Dataset) is the major abstraction that Spark provides to
handle distributed data processing. The examples of RDD API include Word count
and Pi Estimation. These are useful in computing extensive tasks and helps in
building datasets of different kinds.
A DataFrame is a collection of distributed data organized into different name
columns. DataFrame API is used by the users to perform different relational
operations.
It is useful for both external data sources and its inbuilt distributed data
collections. This is used without giving specific instructions for data- processing. It
includes examples like text search & simple data operations.
Sparks MLib or Machine Learning library provides different types of distributed
ML algorithms. Such as extraction, classification, regression, clustering, etc.
Moreover, it also provides tools like ML pipelines to building workflows.
Distributed data processing with Spark
As we know that Apache Spark is a distributed data processing engine, we will
discuss the way of the data processing done using Spark. To speed up the data
processing, we need to use the Apache Spark processing framework. At first, we
need to install and run it.
Resource management
Most of the jobs in Spark are run on a shared processing cluster that will
distribute available resources. It allocates among all running jobs based on some
parameters.
Moreover, we need to allocate memory to the executor where there are two
relevant settings:
The size of memory available for the Spark 'Java' process is --executor-
memory 1G
The amount of memory required for Python or R script is: --conf
spark.yarn.executor.memory Overhead=2048
Number of parallel jobs
The number of jobs that are parallel processed identified dynamically with spark.
Therefore, we should use the following parameters:
--conf spark.shuffle.service.enabled =true –conf
spark.dynamicAllocation.enabled=true
There is an option that we can set upper or lower bounds also:
--conf spark.dynamicAllocation.maxExecutors =30 --conf
spark.dynamicAllocation. minExecutors=10
Number of dependencies
There are a lot of commonly used Python dependencies require to preinstall on
the cluster. But in some cases, we can provide our own.
To do this, we need to get a package containing our dependency. Besides, the
PySpark supports zip, egg, or whl packages only. Using pip, we can get such a
package easily.
pip download Flask==1.0.2
Now it will download the package including all of its dependencies. Pip prefers to
download a wheel if it is available, but it may also return a ".tar.gz" file, which we
will need to repackage it as zip or wheel.
To repackage a tar.gz as wheel we need to do:
tar xzvf package.tar.gz
cd package
python setup.py bdist_wheel
But, the above files depend on the version of Python we use. So, we need to
install a higher version of Python for this. In this way, we came to know how
distributed data processing is actually done.
Spark architecture
It includes a well-defined layered architecture that comprises of loosely coupled
components and layers. It also integrates various extensions and libraries. The
Apache Spark Architecture is based on the following abstractions-
Resilient Distributed Datasets (RDD)
Directed Acyclic Graph (DAG)
Resilient Distributed Datasets (RDD)
The Resilient Distributed Datasets or RDD is a collection of data sets split into
partitions. These are stored in memory on worker nodes of the Apache spark
cluster. In terms of datasets, it supports two types of RDD’s – (a) Hadoop
Datasets, created from the files stored on HDFS. (b) Parallelized collections, that
are based on existing Scala collections. Moreover, the RDD’s support two
different kinds of operations –
-Transformations
- Actions
DAG (Directed Acyclic Graph)
DAG or Directed Acyclic Graph is a series of computations that perform on data.
In this, each node is a partition RDD & the edge is a transformation on top of data.
Advantages of Distributed Data Processing
The distributed data processing helps in the allocation of data among different
computer- networks in different locations for sharing data processing capability.
There are many advantages of distributed data processing. Such as;
Reliable
In a single-server or system processing, there may be some hardware issues and
software crashes that cause malfunction and failure. Moreover, it also results in a
complete system breakdown. But, the distributed data processing is much reliable
due to different control centers spread across different systems. A disruption in
any one system does not impact the network since another system takes over its
processing capability. Furthermore, it makes the distributed data processing
system more reliable and powerful.
Lower Cost
In large companies it needs to invest expensive mainframe and supercomputers
to function as centralized servers in business operations. Each mainframe
machine costs several hundred thousand $ in comparison to several thousand $
for a few mini computers. Again distributed data processing helps to lower the
cost of data sharing and networking across the organization. It comprises several
minicomputer systems that cost less than a mainframe machine.
More Flexible
Many individual computers that comprise a distributed network present at
different places. For example, an organization with a distributed network system
comprises 3 computer systems having each machine in a different branch. These
three machines are interconnected through the Internet. And they can process
data in parallel but from different locations. This makes us understand distributed
data-processing networks more flexible to use.
Moreover, this system is flexible also in terms of enhancing or minimizing
processing capability. For example, by adding more nodes or computers to the
network enhances its processing power. But reducing computer systems from the
network minimizes its processing power.
Performance improvement and Reduced Processing Time
A single computer system is limited in its performance and efficiency but adding
another computer to a network enhances power processing. By adding one more
system will further enhance performance. So, distributed data processing works
on this principle and makes that a task gets done faster if different machines are
working in parallel.
For instance, complex statistical problems are broken into different modules and
allocated to different machines where they are processed in parallel. This
significantly minimizes processing time and improves the performance of the
computer.
Conclusion
Thus, we reach a conclusion in the above article that explains the process of
distributed data processing using Spark. Learn more things from big data hadoop training.