Hadoop 2.0 boasts improved scalability and device availability across a collection of bundled tools reflecting a generational change in the Hadoop architecture with the launch of YARN. Hadoop 2.0 also provides the solution to the much awaited problem of High Availability.
Hadoop introduced YARN-which is capable of processing terabytes and Petabytes of data present in HDFS using various non-MapReduce applications, including GIRAPH and MPI.
Hadoop 2.0 splits the overloaded Work Tracker's roles into two separate divine components i.e. the Task Master (per program) and the Global Resource Manager.
Hadoop 2.0 increases the horizontal scalability of the Name Node via HDFS Federation and removes the Name Node High Availability Single Point Failure Problem
Hadoop 1.0 Name Node and the issue with the high availability:
Hadoop 1.0 Name Node has a single failure point (SPOF) problem- that means that if the Name Node fails, then the Hadoop Cluster becomes out of the way. However, you may consider an unusual event as applications for all Name Node servers use business critical hardware with RAS features (reliability, availability, and serviceability). In case, if Name Node failure in hadoop occurs then the Hadoop Administrators need manual intervention to recover the Name Node with the aid of a secondary Name Node.
Name Node SPOOF problem restricts the Hadoop Cluster’s total availability in the following ways.
If there are any scheduled hardware or software update maintenance activities on the Name Node then the Hadoop Cluster will result in total downtime.
When any unplanned event occurs that will cause the system to crash, then the Hadoop cluster will not be available until you restart the Name Node by the Hadoop Administrator.
Hadoop 2 High Availability
Hadoop 2.0 overcomes this shortcoming in the SPOF by providing multiple Name Nodes support. It introduces Hadoop 2.0 High Availability feature that brings to the Hadoop Architecture an extra Name Node (Passive Standby Name Node) configured for automatic failover.
The main motive of the Hadoop 2.0 High Availability project is to render availability to large data applications 24/7 through the deployment of 2 Hadoop Name Nodes. One in active configuration and the other is the passive Standby Node.
Earlier there was one Hadoop Name Node for maintaining the HDFS file tree hierarchy and tracking the cluster data storage. Hadoop 2.0 High availability enables users to configure uncalled- Hadoop clusters for Name Nodes in order to reduce the possibility of SPOF in a given Hadoop cluster. The Hadoop Cluster framework enables users to create clusters horizontally with several Name Nodes that can run autonomously across a common data storage pool, offering improved scalability computing compared to Hadoop 1.0.
Hadoop 2.0 now configures Hadoop architecture in a way that supports automatic failover with full stack durability and a hot Standby Name Node.
Hadoop Namenode high availability
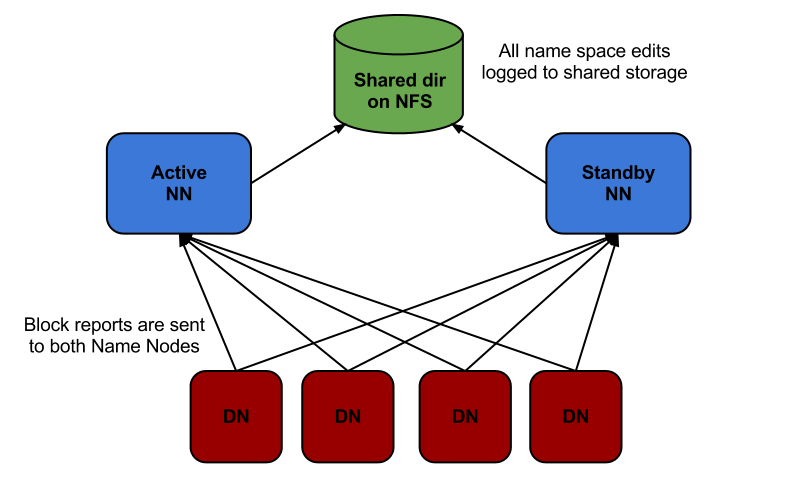
From the graph above, it is evident that both the active and passive (Standby) Name Nodes have state-of-the-art metadata that ensures flawless failover for large Hadoop clusters, implying that there would be no downtime for your Hadoop cluster, and that it will be accessible throughout.
Hadoop 2.0 is important to detect any vulnerability in the Name Node host and processes, so that it can turn to the passive Name Node, i.e. the Standby Node, automatically to ensure high availability of the HDFS resources for big data applications. It is time for Hadoop Administrators to take a breather with the introduction of Hadoop 2.0 HA, since this method does not need manual intervention.
The full Hadoop Stack i.e. with HDP 2.0 High Availability. HBase, Pig, Hive, MapReduce, Oozie are prepared to tackle the problem of Name Node failure- without losing the progress of the job or any related data. Thus, the failure of the Name Node does not affect any vital long running jobs to complete at a particular time.
Hadoop High Availability features
The Hadoop Namenode High availability features are as follows.
Hadoop users High dispensability expectations from Hadoop 2.0
Once Hadoop users use Hadoop 2.0 Architecture's High Availability Requirements, some of the most important High Availability specifications they had come up with were:
No Data Loss / No Job Failure / No Downtime
Hadoop users stated that Hadoop 2.0 High Availability should ensure that any individual software or hardware failure causes no impact on the applications.
Cover for Numerous Defects
Hadoop users claimed that the Hadoop cluster has to be able to stand for more than one failure simultaneously with Hadoop 2.0 High Availability. Preferably, Hadoop configuration must allow the administrator to configure the degree of tolerance, or allow the user to make a resource-level choice-how many failures the cluster can tolerate.
Failed self-recovery
Hadoop users claimed that the Hadoop cluster would recover automatically (self-healing) with Hadoop 2.0 High Availability without any manual intervention to restore it to a highly available state after the failure, with the pre-assumption that adequate physical resources are already usable.
Quick to install
The setting up of High Availability should be a trifling operation, according to Hadoop users, without allowing the Hadoop Administrator to install any other open source or commercial third party software.
No Hardware Specifications required
Hadoop users say Hadoop 2.0 High Availability feature does not allow additional hardware install, maintain or purchase by users. You may need no further dependencies that will exist on non-commodity hardware such as Load Balancers.
Deploying High availability Hadoop, two clusters:
Begin the daemons for Journal Node on those machine set where the JNs are deployed. Execute the following command on every machine.
Su – l hdfs –/ hdfs-daemon.sh start newsletter'
Wait on each of the JN machines for the daemon to start.
Render JournalNodes initialized.
Execute the following command at NN1 host machine:
Su – l hdfs initializeSharedEdits -arm'
This command sizes all of the JournalNodes. It is achieved in an interactive way by default, the command prompts users to confirm the format for the "Y / N" data. Using option -force or -nonInteractive you can skip the prompt.
It also copies all the edits data from local NameNode (NN1) edit directories to JournalNodes after the most recent checkpoint.
Initialize HA in ZooKeeper state. On NN1 perform the following command.
hdfs zkfc -formatZK –force
In ZooKeeper, this command generates a Znode. Stores of the failover system use this znode to store data.
Test to see if they run ZooKeeper. If not, start ZooKeeper by running the following command on the host machine(s) in ZooKeeper.
su - zookeeper -c "export ZOOCFGDIR
Run the following command at the standby namenode host.
Su-l hdfs -c "hdfs -bootstrapStandby -power"
Starting NN1. Execute the following command on host NN1.
Su -l hdfs - / hdfs-daemon.sh start namenode"
Make sure NN1 runs correctly.
Format NN2 and copy the latest NN1-NN2 checkpoint (FSImage) with the following command.
Su-l hdfs -"hdfs -bootstrapStandby -power"
This command connects to HH1 to get the namespace metadata and fsimage. This command also ensures that NN2 receives adequate JournalNodes editlogs (corresponding to fsimage). This command fails if JournalNodes is not initialized correctly and can not provide editlogs.
To Start NN2 execute the command on the NN2 host machine.
su -l hdfs - / hadoop-daemon.sh start namenode"
Ensure NN2 runs correctly.
If you are deploying NN3, repeat steps 5 and 6 for NN3.
DataNodes launch. Execute the following DataNodes command.
Su -l hdfs - / hadoop-daemon.sh"
Validate setup HA.
Switch to the NameNodes web pages individually by searching their HTTP addresses. Under the configured address mark, see the NameNode's HA condition. NameNode can be either "standby" or "active."
Conclusion
I hope you reach to a conclusion about High availability clusters in Hadoop. You can learn more through big data and hadoop online training
No comments:
Post a Comment