In this lesson, we will discuss New in Hadoop: You should know the Various File Format in Hadoop.
Afew weeks ago, I wrote an article about Hadoop and talked about the different parts of it. And how it plays an essential role in data engineering. In this article, I’m going to give a summary of the different file format in Hadoop. This topic is going to be a short and quick one. If you are trying to understand, how’s Hadoop work and it’s a vital role in Data Engineer, please visit my Article on Hadoop here or happy to skip it. Apache spark
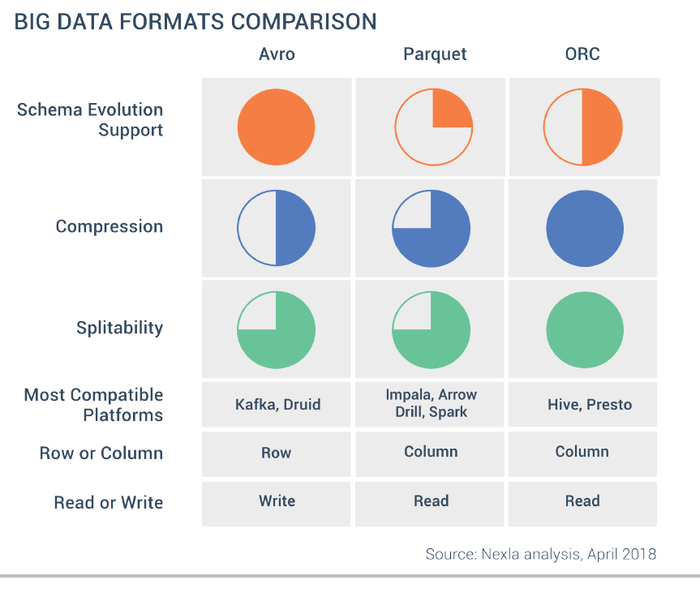
The file format in Hadoop roughly divided into two categories: row-oriented and column-oriented:
Row-oriented:
The same row of data stored together that is continuous storage: SequenceFile, MapFile, Avro Datafile. In this way, if only a small amount of data of the row needs to be accessed, the entire row needs to be read into the memory. Delaying the serialization can lighten the problem to a certain amount, but the overhead of reading the whole row of data from the disk cannot be withdrawn. Row-oriented storage is suitable for situations where the entire row of data needs to be processed simultaneously.
Column-oriented:
The entire file cut into several columns of data, and each column of data stored together: Parquet, RCFile, ORCFile. The column-oriented format makes it possible to skip unneeded columns when reading data, suitable for situations where only a small portion of the rows are in the field. But this format of reading and write requires more memory space because the cache line needs to be in memory (to get a column in multiple rows). At the same time, it is not suitable for streaming to write, because once the write fails, the current file cannot be recovered, and the line-oriented data can be resynchronized to the last synchronization point when the write fails, so Flume uses the line-oriented storage format.
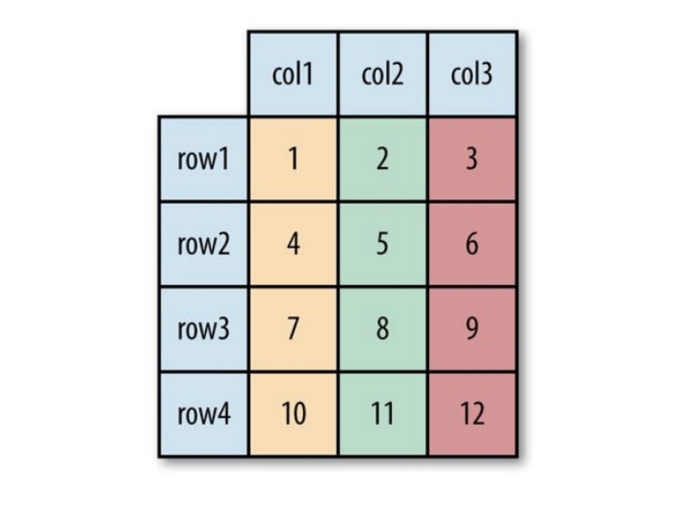

Picture 1.(Left Side )Show the Logical Table and Picture 2. ( Right Side) Row-Oriented Layout(Sequence File)
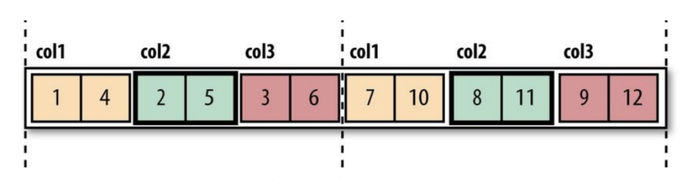
Picture 3. Column-oriented Layout (RC File)
If it still not clear what is row and column oriented, don’t worry,
Here are a few related file formats that are widely used on the Hadoop system:
To big data course visit:big data hadoop course.
Sequence File
The storage format differs depending on whether it is compressed, and whether it uses record compression or block compression:
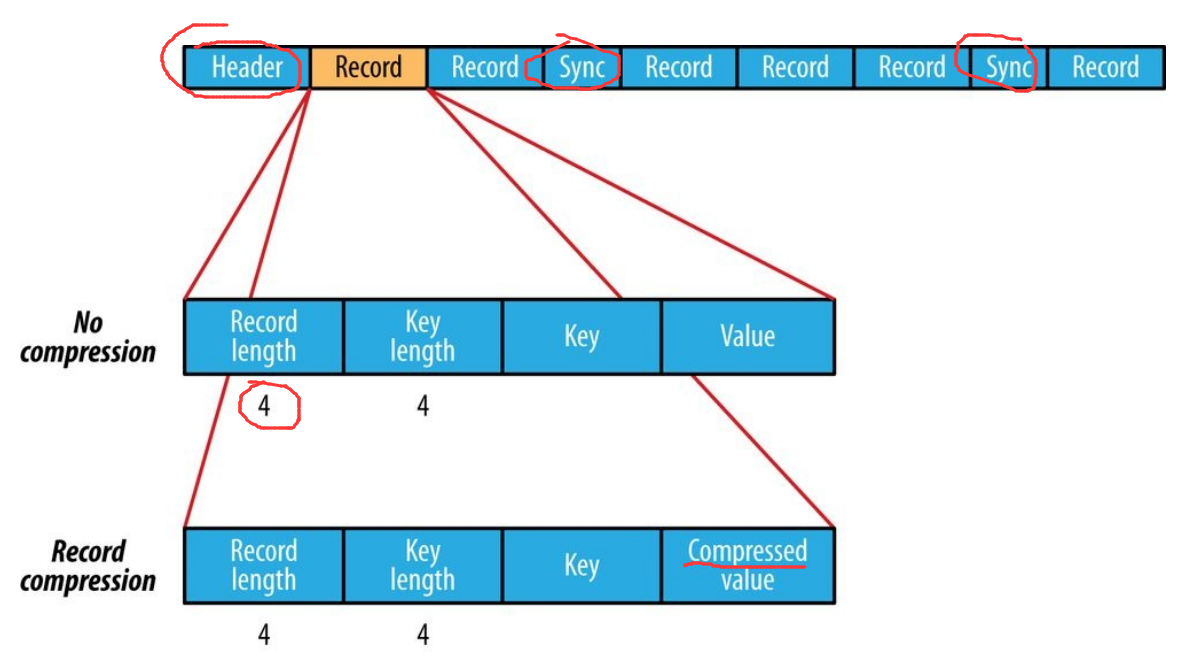
The Internal structure of a sequence file with no compression and with record compression.
No compression:
Store in order according to record length, Key length, Value degree, Key value, and Value value. The range is the number of bytes. Serialization is performed using the specified Serialization.
Record compression:
Only the value is compressed, and the compressed codec stored in the header.
Block compression:
Multiple records are compressed together to take advantage of the similarities between records and save space. The synchronization flag is added before and after the block. The minimum value of the block is io.seqfile.compress.blocksizeset by the attribute.
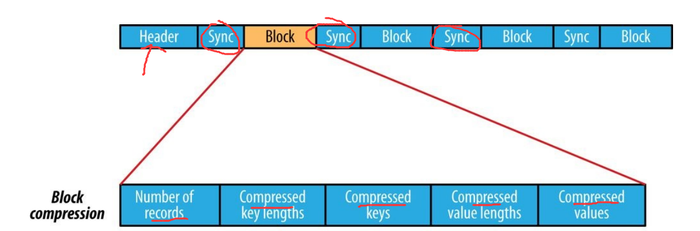
The internal structure of a sequence file with block compression
Map File
MapFile is a variant of SequenceFile. It is MapFile after adding an index to SequenceFile and sorting it. The index is stored as a separate file, typically storing an index for every 128 records. Indexes can be loaded into memory for quick lookups — the files storing the data arranged in the order defined by Key.
MapFile records must be written in order. Otherwise, an IOException is thrown.
Derived type of MapFile:
- SetFile : A special MapFile for storing a sequence of keys of type Writable. Key is written in order.
- ArrayFile: Key is an integer representing the position in the array, and value is Writable.
- BloomMapFile: Optimized for the MapFile get() method using dynamic Bloom filters. The filter stored in memory, and only when the key value exists, the regular get() method is called to perform the read operation.
The files listed below the Hadoop system include RCFile, ORCFile, and Parquet. The column-oriented version of Avro is Trevni.
RC File
Hive’s Record Columnar File, this type of file first divides the data into Row Group by row, and inside the Row Group, the data is stored in columns. Its structure is as follows:
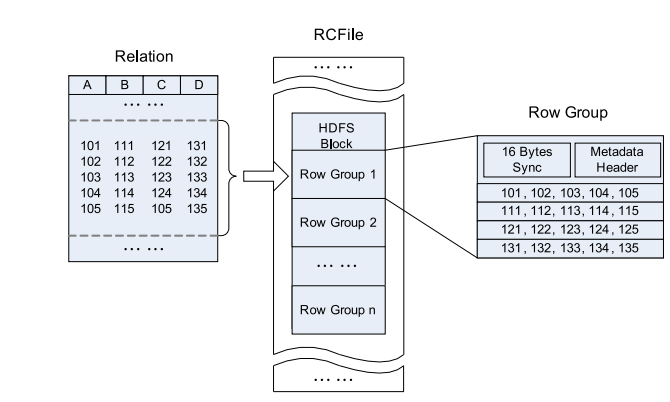
Data Layout of RC File in an HDFS block
Compared to purely row-oriented and column-oriented:
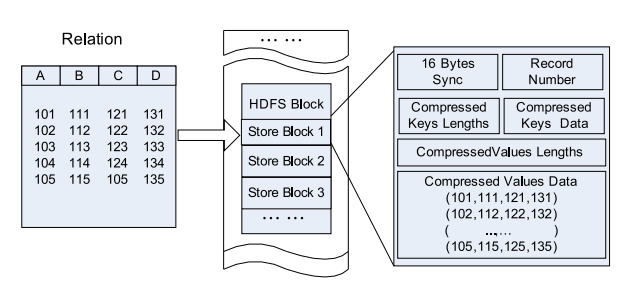
Row-Store in an HDFS Block
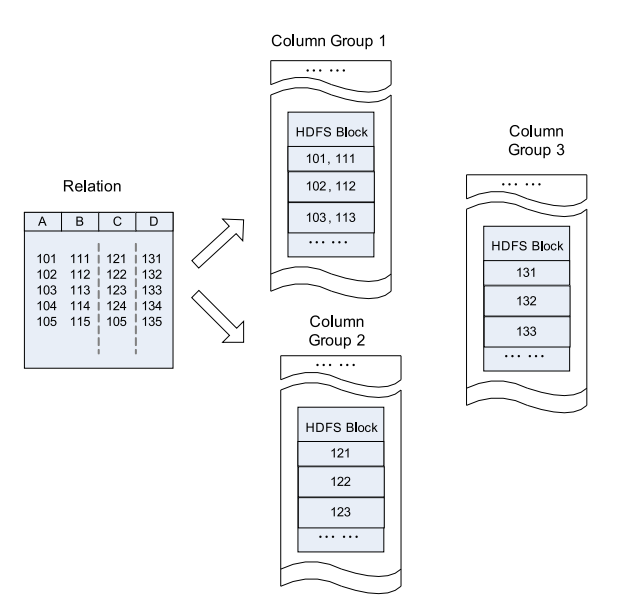
Column Group in HDFS Block
ORC File
ORCFile (Optimized Record Columnar File) provides a more efficient file format than RCFile. It internally divides the data into Stripe with a default size of 250M. Each stripe includes an index, data, and Footer. The index stores the maximum and minimum values of each column, as well as the position of each row in the column.
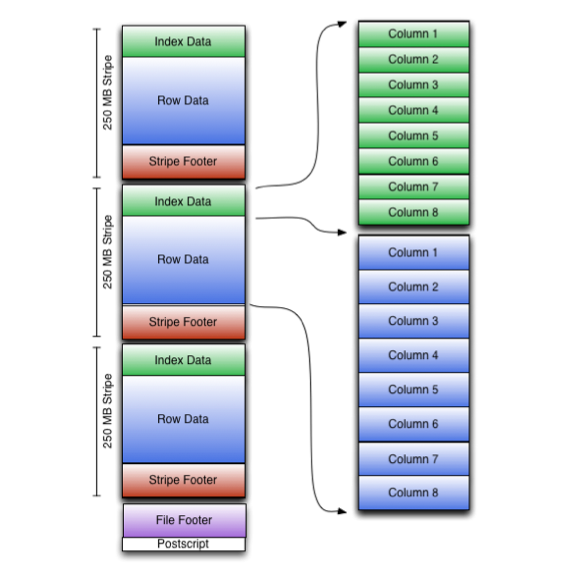
ORC File Layout
In Hive, the following command is used to use ORCFile:
CREATE TABLE ...STORED AAS ORC ALTER TABLE ... SET FILEFORMAT ORC SET hive.default.fileformat=ORCParquet
A generic column-oriented storage format based on Google’s Dremel. Especially good at handling deeply nested data.
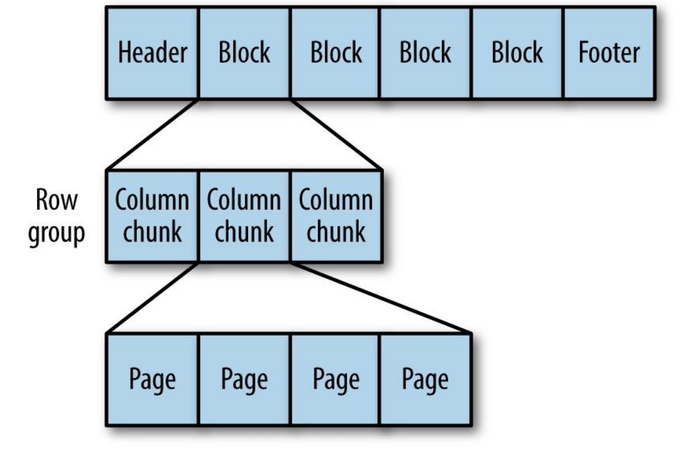
The internal Structure of Parquet File
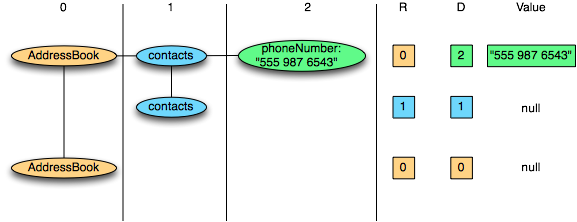
For nested structures, Parquet converts it into a flat column store, which is represented by Repeat Level and Definition Level (R and D) and uses metadata to reconstruct the record when reading the data to rebuild the entire file. Structure. The following is an example of R and D:
AddressBook { contacts: { phoneNumber: "555 987 6543" } contacts: { } } AddressBook}
To get more information visit:big data hadoop training.
No comments:
Post a Comment