Apache Spark is a Hadoop MapReduce based lightning-speed cluster computing technology, designed for fast computation. Moreover, it extends the MapReduce model to effectively use it for different types of calculations including interactive queries and stream processing. The main feature of Spark is its in-memory cluster
computing that improves the processing speed of an application.
This is designed to cover different range of workloads like batch apps, iterative algorithms, influencing queries, etc. Apart from supporting all these workload in a respective system, it also minimizes the burden of maintaining individual tools for the management.more info visit:big data online training.
Features of Apache Spark
The following are the best features of Spark;
Speed – Spark helps to run an application within the Hadoop cluster, up to 100 times faster in memory, and 10 times quicker while running on disk. This is possible by minimizing numerous read/write operations to disk. It stores the
midway processing data within a memory.
Supports different languages – It gives built-in APIs in Java, Scala, or Python languages. Therefore, users can write applications in different programming languages. Moreover, Spark also includes 80 high-level operators for interactive querying purpose.
Advanced Analytics − Spark does not only support ‘Map’ and ‘reduce’ but also supports SQL queries, Machine learning (ML), and Graph algorithms.
Hadoop Integration – Apache Spark can work with number of files stored within HDFS.
Spark’s Interactive Shell – This is written in Scala, and includes an own version of the Scala interpreter.
Resilient Distributed Datasets (RDD’s) – These are allocated objects that may be cached in-memory, across a cluster of compute nodes. Besides, they are the primary data objects used under the Spark app.
Distributed Operators – Besides MapReduce, many other operators are there who can use on Resilient Distributed Datasets.
Using Apache Spark with Hadoop
Apache Spark easily fits into the Hadoop open-source community system, built on top of the HDFS. However, it is not related to the two-stage MapReduce model, and promises performance up to 100 times faster than Hadoop MapReduce for precise applications.
Well suited to ML algorithms – Spark provides small geometry shapes for in- memory cluster computing. This allows user programs to input data into a cluster’s memory and query it repeatedly.
Run 100 times faster – Being analysis software it can also accelerate jobs that run on the Hadoop data-processing platform. Apache Spark also provides the ability to build data-analysis jobs running 100 times faster than those running on the standard Apache Hadoop MapReduce. Moreover, MapReduce has been widely denounced as a hurdle in Hadoop cluster. Because it executes jobs in batch mode, and as a result real-time analysis of data is not possible.
Substitute to MapReduce – Spark provides a substitute for MapReduce. It executes jobs in short span of small-batches that take five seconds or less. Moreover, it also provides real-time stability than stream-oriented Hadoop frameworks like Twitter Storm. The software is useful for different type of jobs, like an ongoing analysis of live data. Here, it needs to thank the software library, more computationally extensive jobs including ML and graph processing.
Multi Language Support – Using Spark, developers can write data-analysis jobs in different pro languages, including more than 80 high-level operators.
Library Support – Spark’s libraries are build to supplement the job processing types being explored more aggressively with the latest commercially supported deployments of Hadoop. MLlib implements a large number of common machine learning algorithms, like clustering; Spark Streaming allows high-speed processing of data absorbed from different sources. And the GraphX enables users for computations on graph data.
SPARK SQL Component – Spark’s SQL component for accessing structured data, enables users the data to be cross-examined along with unstructured data within analysis work. Moreover, this is available only in alpha at present, allows SQL-like queries to be run against data stored in Apache Hive. Obtaining data from Hadoop
via SQL queries is just another variant of the real-time querying functionality hoping up around it.
Apache Spark Compatible with Hadoop– the Spark app is completely comfortable with Hadoop’s DFS along with other Hadoop components; like YARN and the
HBase allocated database.
Spark Application Cluster Options
Spark applications run locally without any allocated processing, locally with different worker threads, and on a cluster.
The Spark application that runs in local mode is shown below in the image.
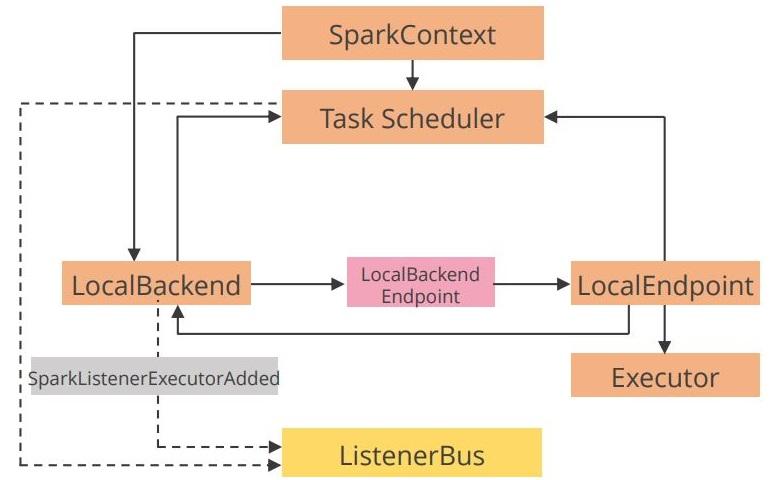
Local mode is useful for building and testing, while the cluster mode is preferred
for production over local mode.
Supported Cluster Resource Managers
There are three different supported cluster resource managers of Spark
applications. These are Hadoop YARN, Spark Standalone, and Apache Mesos.
Hadoop YARN
Hadoop YARN is included under the Cloud Distribution Hadoop (CDH). This is most
commonly useful for production sites. It also enables sharing cluster resources
with other apps.
Spark Standalone
Spark Standalone comes under the Spark. This has limitations in configuration and
scalability but it is easy to install and run. It is useful for testing, building, or small
systems. Although, there is no security support in this type of resource manager.
Apache Mesos
Apache Mesos was the first platform that has Spark support. However, at present,
it is not as popular as the other RMs.
In the below section of the article, we will learn how to run Spark on Hadoop
YARN, both in client and cluster modes.
Running Spark app on YARN:- Client Mode
The resource manager opens the app master that opens the executors and executes the program well.
Running a Spark App Locally
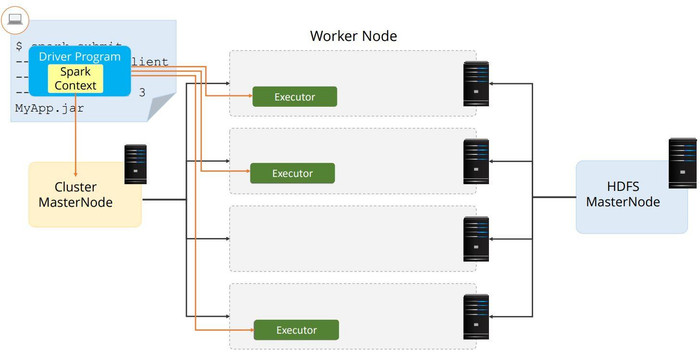
To run a Spark application in local mode, we have to use spark-submit--master to mention the cluster options.
The following are the different local options available:
Use “local [*]” to run the app in local with different threads like cores.
Moreover, it is a default option.
Use “local[n]” to run the application in local mode with n threads.
Use @local@ to run the application in local mode using a single thread.
Running a Spark App on a Cluster
To run a Spark app on a cluster mode, we have to use spark-submit--master to specify the cluster option. The different cluster options available are:
Yarn-client
Yarn-cluster
spark://masternode:port useful within Spark Standalone
mesos://masternode:port useful in Apache Mesos.
Start an Application on a Cluster
We do not only able run an application on a cluster, but can also run a Spark shell
on a cluster. Here, both pyspark and spark-shell includes a --master option.
Configuring Your Application
Spark provides number of properties to Config application. The following are a few example properties, some of which include reasonable default values.
spark.master – This controls the Spark processing workflow.
spark.app.name – it provides an application name, displays within the UI, and stores log data.
spark.local.dir – it shows the location to store local files, like shuffle output. The slash tmp is the default one.
spark.ui.port – this is useful to run the Spark Application UI. The port is useful for app’s dashboard that displays memory and workload data.Moreover, the default port is 4040.
spark.executor.memory – this indicates the amount of memory to distribute to each executor process. The default memory is 1g
spark.driver. memory – it displays the amount of memory to distribute to the driver under client mode. This is the memory useful for the driver process, where SparkContext is started.
Moreover, the Spark applications are configured declaratively or programmatically also.
Final Words
The above details explain how to implement Spark application in Hadoop. It gives the basic idea of understanding Hadoop and Spark applications and its deployment. Get more insights from big data and hadoop online training.
No comments:
Post a Comment