Hadoop ecosystem is a widely used Big Data framework. It is a platform that
involves solving various Big Data problems. The Hadoop ecosystem comprises
many components and services that support Big Data in different ways.
To learn big data hadoop tutorial course visit:big data and hadoop course
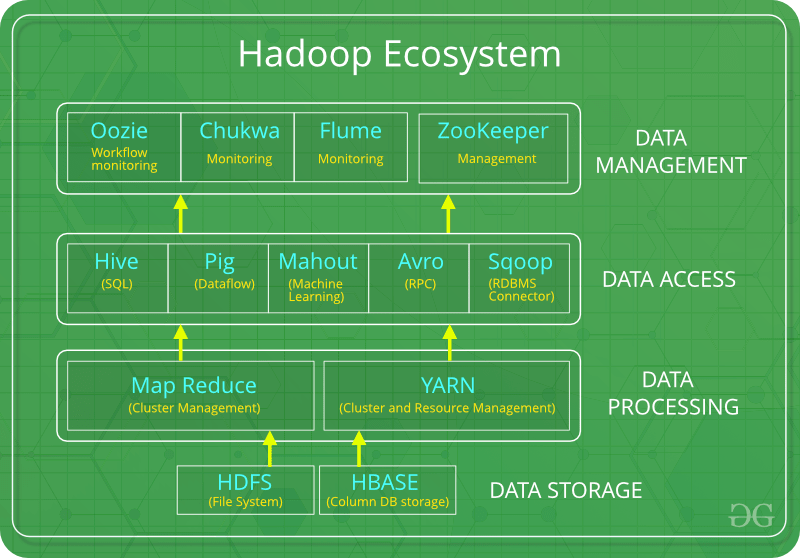
Hadoop has created its place in the industry that performs various tasks on large data sets. These data sets are very sensitive and need efficient handling at every stage. Hadoop ecosystem is a framework that enables users to process large datasets that reside in the form of clusters. Moreover, it includes Apache projects and various commercial tools and solutions that are useful in Big Data. There are four major and different components of Hadoop. Such as HDFS, MapReduce, YARN,and Common. Most of the tools are used as a support to these majorcomponents. Moreover, these tools work closely to provide various services suchas analysis, storage, and maintenance of data.
Hadoop ecosystem tools
There are many tools or components of the Hadoop ecosystem. The following
components collectively form a Hadoop ecosystem;
⮚ HDFS: It refers to the Hadoop Distributed File System
⮚ YARN: It refers to Yet Another Resource Negotiator
⮚ MapReduce: It’s programming based Data Processing system
⮚ PIG & HIVE: These include query-based processing of data services
⮚ HBase: It’s a NoSQL Database
⮚ Mahout, Spark MLLib: These are Machine Learning algorithm libraries
⮚ Zookeeper: It’s a managing cluster
⮚ Oozie: It performs Job Scheduling tasks
Moreover, there are many other components of the Hadoop ecosystem. All these components revolve around the data only. Let us check into these components in detail.
HDFS
HDFS is one of the major components of the Hadoop ecosystem. It is mainly
responsible for storing large datasets of different types. Such as, structured or
unstructured data. This data is stored across different nodes and thereby it
maintains the metadata within log files.
HDFS includes two core components i.e.
● Name node
● Data Node
Name Node is the prime node that contains metadata. It requires only a few
resources than the data nodes that store the actual data. The Data nodes are the storage of data which is commodity hardware in the distributed environment. This makes Hadoop cost-effective and the best usage.
HDFS works as the heart of the system that maintains coordination between theclusters and hardware for smooth functioning.
YARN
It refers to Yet Another Resource Negotiator. The YARN helps to manage the
different resources across the clusters. Moreover, it performs scheduling and
resource allocation for the Hadoop ecosystem.
YARN consists of three major components. These are;
● Resource Manager
● Nodes Manager
● Application Manager
Resource manager works at a cluster level that helps to allocate resources for the applications within a system. It takes the various job submissions and speaks to the containers for the execution of applications. The Node manager works on the allocation of those resources such as CPU, memory, bandwidth, etc and informs the same to the resource manager. Moreover, the Application manager works as a mediator between the resource and node manager. It performs negotiations as per the requirement of these managers.
MapReduce
MapReduce acts as a core factor in the Hadoop ecosystem. It makes the use of
distributed and parallel algorithms to carry on the process of logics. Moreover, it helps to write various applications that transform big data sets into manageable resources.
MapReduce includes two different functions such as Map and Reduce. These
functions perform in the following way.
Map function performs sorting and filtering of various data. Thereby it produces them in the form of a group. The Map helps to generate a key-value result which is later processed by the Reduce method.
Reduce function acts to summarize map data by aggregating it. In simple means, the Reduce method accepts the output generated by Map as input. Moreover, it helps to convert one set of data to another that breaks down the elements into different tuples.
Mahout
Mahout allows Machine Learning applications to a system. Machine Learning
helps the system to learn and develop itself based on different patterns, user
interactions, etc. The system provides various functions such as collaborative filtering, clustering, and classification. These are the concepts of Machine
learning. Moreover, it allows the command line to deploy various algorithms as per users' needs with the help of its libraries.
HIVE
The HIVE performs reading and writing of large data sets. It does so with the help of SQL methodologies. Moreover, its query language is known as HQL (Hive Query Language) is highly scalable and it allows both real-time and batch processing. Besides, Hive supports all the SQL data types and makes the query processing easier.
HBase
HBase is a kind of NoSQL database that supports all kinds of data. It can handle any type of Hadoop Database. Moreover, it provides capabilities of Google’s Big Table that makes it to work on Big Data sets more effectively. At the time of need to search or retrieve something small data in a huge database, those requests must be processed within a short period. Here, HBase comes handy as it gives us a dynamic and capable way of storing limited or useful data.
Zookeeper
The Apache Zookeeper acts like a coordinator for any Hadoop work. It includes a combination of various services and features of the Hadoop Ecosystem. Moreover, it supports and works closely with different services within a distributed environment. It was very hard and time-consuming to coordinatebetween various services in the Hadoop Ecosystem in the earlier times.
But the introduction of Zookeeper made this easier. It saves a lot of time by
performing various tasks like synchronization, grouping, naming, etc. It’s easy to simple to use a service that helps to build powerful solutions. Many giant entities use this service for the whole data flow.
Oozie
Oozie is one of the components of the Hadoop ecosystem that works as a job
scheduler. It schedules various jobs and binds them under a single unit. It
comprises two major jobs such as workflow and coordinator jobs. The Oozie
workflow performs the jobs sequentially as ordered whereas Coordinator jobs
triggered at the time of any external data are given to them.
Avro
Avro is an open-source project. It provides various services related to data
serialization and data exchange for the Hadoop ecosystem. By using the
serialization process many service programs can serialize their data into different files. Hence, this feature makes it easy for the programs to understand the information stored in the Avro file.
This provides the following features:
● It provides a container file that stores persistent data.
● This component provides a remote procedure call also.
● Moreover, it gives rich data structures.
● The concept gives compact, fast, and a binary data format to understand by
programs.
Pig in Hadoop ecosystem
Here, the Pig is one of the components of the Hadoop ecosystem. The pig was
developed to work on a pig Latin language. It is a query-based language similar to SQL language. Pig is a platform that structures the data flow, processes, and analyzes large data sets. Pig platform helps to execute commands.
Moreover, it also takes care of all the activities of MapReduce. As the process
ends, pig stores the result in HDFS. The Latin language is specially designed for this framework. It runs on Pig Runtime similarly the way Java runs on the JVM. Besides, it helps to get easy programming and optimization of various tasks. Hence, it is a major component of the Hadoop Ecosystem. The component is very extensible, self-optimizing, and capable of handling different kinds of data.
Thus, it gives us an idea of the Hadoop ecosystem in Big Data that is useful in
many ways to the industry. Its various components help to form an ecosystem
that comprises various features and functions. Each of the components serves
different purposes and makes the job done for the users. Due to the use of these components, the Hadoop job becomes easier.
To get more insights into Hadoop and its components get into big data hadoop online training from online resources. This learning may help to enhance the skills in Hadoop and paves the way for a better career.
No comments:
Post a Comment