In this lesson, we will discuss MapReduce Combiner
Combiner of MapReduce
Through this part of the MapReduce tutorial you will learn what is a combiner, workflow of a combiner, mapping phase, reducing phase and more.
What is MapReduce Combiner?
It is a localized optional reducer. It used mapper intermediate keys and applies a user method to combine the values in smaller segment of that particular mapper.
For complete Hadoop Tutorials:hadoop admin online training
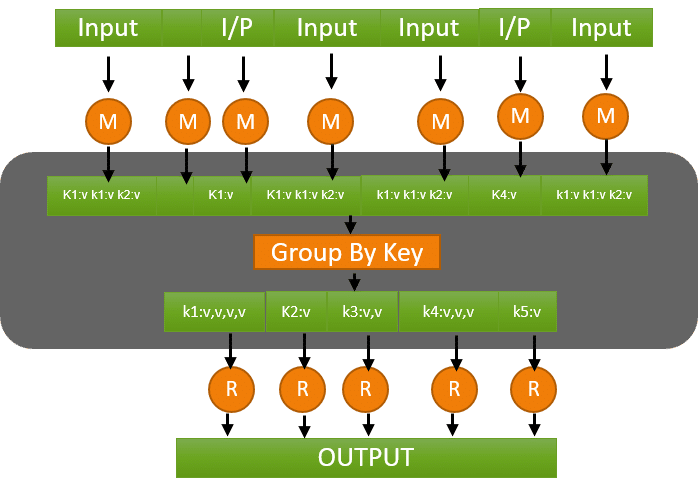
Many repeated keys are produced by maps. It is often useful to do a local aggregation process done by specifying combiner. The goal of the combiner is to decrease the size of the data. It has the same interface as reducer and often are the same class.
Method: conf.setCombinerClass(Reduce.class);
Work flow of combiner:
- It has not predefined interface and it implements reduce( ) method
- Each map output key-value operated by combiner and the output key-value is same as reducer class
- A combiner produces a summary of large data set.
Implementation: use below input.txt input text file.
What do you mean by Object
What do you know about Java
What is Java Virtual Machine
How Java enabled High Performance
What do you mean by Object
What do you know about Java
What is Java Virtual Machine
How Java enabled High Performance
Input: line by line text
Output : forms the key-value pairs
<1, What do you mean by Object
<2 , What do you know about Java
<3, What is Java Virtual Machine
<4, How Java enabled High Performance
There are three important phases in the combiner
<2 , What do you know about Java
<3, What is Java Virtual Machine
<4, How Java enabled High Performance
There are three important phases in the combiner
- Map phase
- Combiner phase
- Reducer phase
Map phase:
Record reader gives the input to this phase and produces the output as another set of key-value pairs.
Record reader is the first phase of MapReduce, it reads every line from the input text file as text.
Input:
<1, What do you mean by Object>
<2 , What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>
Mapper class and map function
<1, What do you mean by Object>
<2 , What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>
Mapper class and map function

We will get the output like

Combiner phase:
This phase takes the map phase output as input and the output of combiner phase is key-value collections pair.so,
Input:
This phase takes the map phase output as input and the output of combiner phase is key-value collections pair.so,
Input:
Use following code to the class declaration of map phase, combiner phase and reduce phase.
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
Output: The expected output is
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
Output: The expected output is

Reduce phase:
This phase takes combiner phase output as input .
Use the following code for reduce phase.
public static class IntSumReducer extends
Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
This phase takes combiner phase output as input .
Use the following code for reduce phase.
public static class IntSumReducer extends
Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
Output:

Record writer: Output
What 3
Do 2
You 2
Mean 1
By 1
Object 1
Know 1
About 1
Java 3
Is 1
Virtual 1
Machine 1
How 1
Enabled 1
High 1
Performance 1
This blog will help you get a better understanding of mapReduce and Hadoop admin tutorials,hadoop admin online course
What 3
Do 2
You 2
Mean 1
By 1
Object 1
Know 1
About 1
Java 3
Is 1
Virtual 1
Machine 1
How 1
Enabled 1
High 1
Performance 1
This blog will help you get a better understanding of mapReduce and Hadoop admin tutorials,hadoop admin online course
ReplyDeleteHello,
Your blog has a lot of valuable information . Thanks for your time on putting these all together.. Really helpful blog..I just wanted to share information about
power bi training