Welcome to the lesson ‘Big Data and Hadoop Ecosystem’ of Big Data Hadoop tutorial which is a part of ‘big data hadoop course’ offered by OnlineITguru. This lesson is an Introduction to the Big Data and the Hadoop ecosystem. In the next section, we will discuss the objectives of this lesson.
Objectives
After completing this lesson, you will be able to:
- Understand the concept of Big Data and its challenges
- Explain what Big Data is
- Explain what Hadoop is and how it addresses Big Data challenges
- Describe the Hadoop ecosystem
Overview to Big Data and Hadoop
Before the year 2000, data was relatively small than it is currently; however, data computation was complex. All data computation was dependent on the processing power of the available computers.
Later as data grew, the solution was to have computers with large memory and fast processors. However, after 2000, data kept growing and the initial solution could no longer help.
Over the last few years, there has been an incredible explosion in the volume of data. IBM reported that 2.5 exabytes, or 2.5 billion gigabytes, of data, was generated every day in 2012.
Here are some statistics indicating the proliferation of data from Forbes, September 2015. 40,000 search queries are performed on Google every second. Up to 300 hours of video are uploaded to YouTube every minute.
In Facebook, 31.25 million messages are sent by the users and 2.77 million videos are viewed every minute. By 2017, nearly 80% of photos will be taken on smartphones.
By 2020, at least a third of all data will pass through the Cloud (a network of servers connected over the Internet). By the year 2020, about 1.7 megabytes of new information will be created every second for every human being on the planet.
Data is growing faster than ever before. You can use more computers to manage this ever-growing data. Instead of one machine performing the job, you can use multiple machines. This is called a distributed system.
You can check the best online training for big data and hadoop course preview here
Let us look at an example to understand how a distributed system works.
How Does a Distributed System Work?
Suppose you have one machine which has four input/output channels. The speed of each channel is 100 MB/sec and you want to process one terabyte of data on it.
It will take 45 minutes for one machine to process one terabyte of data. Now, let us assume one terabyte of data is processed by 100 machines with the same configuration.
It will take only 45 seconds for 100 machines to process one terabyte of data. Distributed systems take less time to process Big Data.
Now, let us look at the challenges of a distributed system.
Challenges of Distributed Systems
Since multiple computers are used in a distributed system, there are high chances of system failure. There is also a limit on the bandwidth.
Programming complexity is also high because it is difficult to synchronize data and process. Hadoop can tackle these challenges.
Let us understand what Hadoop is in the next section.
What is Hadoop?
Hadoop is a framework that allows for the distributed processing of large datasets across clusters of computers using simple programming models. It is inspired by a technical document published by Google.
The word Hadoop does not have any meaning. Doug Cutting, who discovered Hadoop, named it after his son yellow-colored toy elephant.
Let us discuss how Hadoop resolves the three challenges of the distributed system, such as high chances of system failure, the limit on bandwidth, and programming complexity.
The four key characteristics of Hadoop are:
- Economical: Its systems are highly economical as ordinary computers can be used for data processing.
- Reliable: It is reliable as it stores copies of the data on different machines and is resistant to hardware failure.
- Scalable: It is easily scalable both, horizontally and vertically. A few extra nodes help in scaling up the framework.
- Flexible: It is flexible and you can store as much structured and unstructured data as you need to and decide to use them later.
Traditionally, data was stored in a central location, and it was sent to the processor at runtime. This method worked well for limited data.
However, modern systems receive terabytes of data per day, and it is difficult for the traditional computers or Relational Database Management System (RDBMS) to push high volumes of data to the processor.
Hadoop brought a radical approach. In Hadoop, the program goes to the data, not vice versa. It initially distributes the data to multiple systems and later runs the computation wherever the data is located.
In the following section, we will talk about how Hadoop differs from the traditional Database System.
Difference between Traditional Database System and Hadoop
The table given below will help you distinguish between Traditional Database System and Hadoop.
Traditional Database System
|
Hadoop
|
Data is stored in a central location and sent to the processor at runtime.
|
In Hadoop, the program goes to the data. It initially distributes the data to multiple systems and later runs the computation wherever the data is located.
|
Traditional Database Systems cannot be used to process and store a significant amount of data(big data).
|
Hadoop works better when the data size is big. It can process and store a large amount of data efficiently and effectively.
|
Traditional RDBMS is used to manage only structured and semi-structured data. It cannot be used to control unstructured data.
|
Hadoop can process and store a variety of data, whether it is structured or unstructured.
|
Let us discuss the difference between traditional RDBMS and Hadoop with the help of an analogy.
You would have noticed the difference in the eating style of a human being and a tiger. A human eats food with the help of a spoon, where food is brought to the mouth. Whereas, a tiger brings its mouth toward the food.
Now, if the food is data and the mouth is a program, the eating style of a human depicts traditional RDBMS and that of tiger depicts Hadoop.
Let us look at the Hadoop Ecosystem in the next section.
Hadoop Ecosystem
Hadoop Ecosystem Hadoop has an ecosystem that has evolved from its three core components processing, resource management, and storage. In this topic, you will learn the components of the Hadoop ecosystem and how they perform their roles during Big Data processing. The
Hadoop ecosystem is continuously growing to meet the needs of Big Data. It comprises the following twelve components:
- HDFS(Hadoop Distributed file system)
- HBase
- Sqoop
- Flume
- Spark
- Hadoop MapReduce
- Pig
- Impala
- Hive
- Cloudera Search
- Oozie
- Hue.
You will learn about the role of each component of the Hadoop ecosystem in the next sections.
Let us understand the role of each component of the Hadoop ecosystem.
Components of Hadoop Ecosystem
Let us start with the first component HDFS of Hadoop Ecosystem.
HDFS (HADOOP DISTRIBUTED FILE SYSTEM)
- HDFS is a storage layer for Hadoop.
- HDFS is suitable for distributed storage and processing, that is, while the data is being stored, it first gets distributed and then it is processed.
- HDFS provides Streaming access to file system data.
- HDFS provides file permission and authentication.
- HDFS uses a command line interface to interact with Hadoop.
So what stores data in HDFS? It is the HBase which stores data in HDFS.
HBase
- HBase is a NoSQL database or non-relational database.
- HBase is important and mainly used when you need random, real-time, read or write access to your Big Data.
- It provides support to a high volume of data and high throughput.
- In an HBase, a table can have thousands of columns.
We discussed how data is distributed and stored. Now, let us understand how this data is ingested or transferred to HDFS. Sqoop does exactly this.
What is Sqoop?
- Sqoop is a tool designed to transfer data between Hadoop and relational database servers.
- It is used to import data from relational databases (such as Oracle and MySQL) to HDFS and export data from HDFS to relational databases.
If you want to ingest event data such as streaming data, sensor data, or log files, then you can use Flume. We will look at the flume in the next section.
Flume
- Flume is a distributed service that collects event data and transfers it to HDFS.
- It is ideally suited for event data from multiple systems.
After the data is transferred into the HDFS, it is processed. One of the frameworks that process data is Spark.
What is Spark?
- Spark is an open source cluster computing framework.
- It provides up to 100 times faster performance for a few applications with in-memory primitives as compared to the two-stage disk-based MapReduce paradigm of Hadoop.
- Spark can run in the Hadoop cluster and process data in HDFS.
- It also supports a wide variety of workload, which includes Machine learning, Business intelligence, Streaming, and Batch processing.
Spark has the following major components:
- Spark Core and Resilient Distributed datasets or RDD
- Spark SQL
- Spark streaming
- Machine learning library or Mlib
- Graphx.
Spark is now widely used, and you will learn more about it in subsequent lessons.
Hadoop MapReduce
- Hadoop MapReduce is the other framework that processes data.
- It is the original Hadoop processing engine, which is primarily Java-based.
- It is based on the map and reduces programming model.
- Many tools such as Hive and Pig are built on a map-reduce model.
- It has an extensive and mature fault tolerance built into the framework.
- It is still very commonly used but losing ground to Spark.
After the data is processed, it is analyzed. It can be done by an open-source high-level data flow system called Pig. It is used mainly for analytics.
Let us now understand how Pig is used for analytics.
Pig
- Pig converts its scripts to Map and Reduce code, thereby saving the user from writing complex MapReduce programs.
- Ad-hoc queries like Filter and Join, which are difficult to perform in MapReduce, can be easily done using Pig.
- You can also use Impala to analyze data.
- It is an open-source high-performance SQL engine, which runs on the Hadoop cluster.
- It is ideal for interactive analysis and has very low latency which can be measured in milliseconds.
Impala
- Impala supports a dialect of SQL, so data in HDFS is modeled as a database table.
- You can also perform data analysis using HIVE. It is an abstraction layer on top of Hadoop.
- It is very similar to Impala. However, it is preferred for data processing and Extract Transform Load, also known as ETL, operations.
- Impala is preferred for ad-hoc queries.
HIVE
- HIVE executes queries using MapReduce; however, a user need not write any code in low-level MapReduce.
- Hive is suitable for structured data. After the data is analyzed, it is ready for the users to access.
Now that we know what HIVE does, we will discuss what supports the search of data. Data search is done using Cloudera Search.
Cloudera Search
- Search is one of Cloudera's near-real-time access products. It enables non-technical users to search and explore data stored in or ingested into Hadoop and HBase.
- Users do not need SQL or programming skills to use Cloudera Search because it provides a simple, full-text interface for searching.
- Another benefit of Cloudera Search compared to stand-alone search solutions is the fully integrated data processing platform.
- Cloudera Search uses the flexible, scalable, and robust storage system included with CDH or Cloudera Distribution, including Hadoop. This eliminates the need to move large datasets across infrastructures to address business tasks.
- Hadoop jobs such as MapReduce, Pig, Hive, and Sqoop have workflows.
Oozie
- Oozie is a workflow or coordination system that you can use to manage Hadoop jobs.
The Oozie application lifecycle is shown in the diagram below.
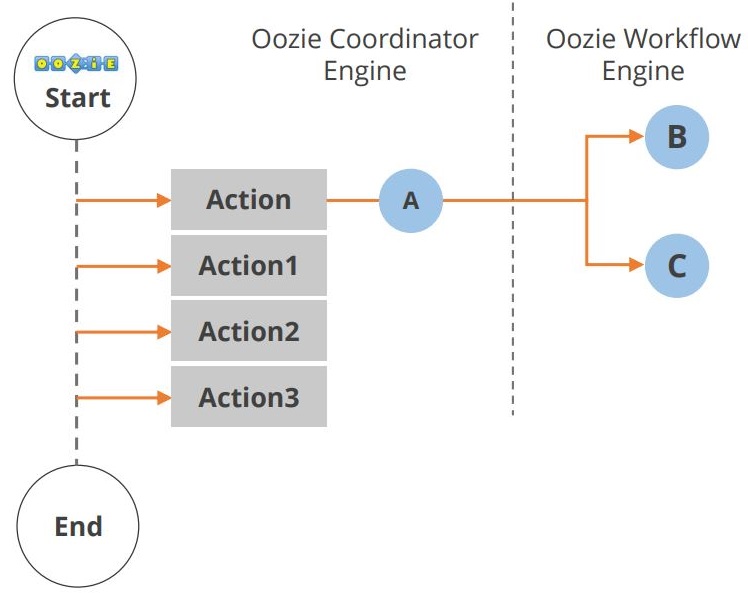 As you can see, multiple actions occur between the start and end of the workflow. Another component in the Hadoop ecosystem is Hue. Let us look at the Hue now.
As you can see, multiple actions occur between the start and end of the workflow. Another component in the Hadoop ecosystem is Hue. Let us look at the Hue now.Hue
Hue is an acronym for Hadoop User Experience. It is an open-source web interface for Hadoop. You can perform the following operations using Hue:
- Upload and browse data
- Query a table in HIVE and Impala
- Run Spark and Pig jobs and workflows Search data
- All-in-all, Hue makes Hadoop easier to use.
- It also provides SQL editor for HIVE, Impala, MySQL, Oracle, PostgreSQL, SparkSQL, and Solr SQL.
After this brief overview of the twelve components of the Hadoop ecosystem, we will now discuss how these components work together to process Big Data.
Stages of Big Data processing
There are four stages of Big Data processing: Ingest, Processing, Analyze, Access. Let us look at them in detail.
Ingest
The first stage of Big Data processing is Ingest. The data is ingested or transferred to Hadoop from various sources such as relational databases, systems, or local files. Sqoop transfers data from RDBMS to HDFS, whereas Flume transfers event data.
Processing
The second stage is Processing. In this stage, the data is stored and processed. The data is stored in the distributed file system, HDFS, and the NoSQL distributed data, HBase. Spark and MapReduce perform the data processing.
Analyze
The third stage is Analyze. Here, the data is analyzed by processing frameworks such as Pig, Hive, and Impala.
Pig converts the data using a map and reduce and then analyzes it. Hive is also based on the map and reduce programming and is most suitable for structured data.
Access
The fourth stage is Access, which is performed by tools such as Hue and Cloudera Search. In this stage, the analyzed data can be accessed by users.
Hue is the web interface, whereas Cloudera Search provides a text interface for exploring data.
Check out the big data hadoop certification course
Summary
Let us now summarize what we learned in this lesson.
- Hadoop is a framework for distributed storage and processing.
- Core components of Hadoop include HDFS for storage, YARN for cluster-resource management, and MapReduce or Spark for processing.
- The Hadoop ecosystem includes multiple components that support each stage of Big Data processing.
- Flume and Sqoop ingest data, HDFS and HBase store data, Spark and MapReduce process data, Pig, Hive, and Impala analyze data, Hue and Cloudera Search help to explore data.
- Oozie manages the workflow of Hadoop jobs.
Conclusion
This concludes the lesson on Big Data and the Hadoop Ecosystem.
No comments:
Post a Comment