Pig Latin is the language used by Apache Pig to analyze data in Hadoop. In this chapter we will discuss the basics of Pig Latin such as statements from Pig Latin, data types, general and relational operators and UDF's from Pig Latin.
Pig Latin Data Model
As discussed in previous chapters, Pig's data model is nested to the full. The Pig Latin data model's outermost structure is a Reference. And it's a case where −
A bag is a Tuple set.
A tuple is a series of directed areas.
A field is just one piece of data.
Pig Latin Statements
Statements are the basic constructs when processing data using Pig Latin.
Those statements function on relationships. They include expressions and schemes.
statement terminates with a semicolon (;).
You will perform various operations via statements, using operators provided by Pig Latin.
With the exception of LOAD and STORE, Pig Latin statements take on a relationship as input while performing all other operations, and generate another relationship as output.
As soon as you enter a Load statement in the Grunt container, it will perform its semantic testing. You need to use the Dump operator to access the contents of the schema. The MapReduce job to load the data into the file system will only be carried out after the dump operation has been completed.More tutorials visit:big data online course.
Example of Pig latin
A statement Pig Latin, which loads data to Apache Pig, is given below.
Grunt > LOAD 'student data.txt' USING PigStorage(')as
(ID: int, first name: chararray, last name: chararray, city: chararray);
Pig Data Types
Pig's data types make up the data model for the way Pig thinks about the data structure it processes. With Pig, when the data is loaded the data model is specified. Any data that you load from the disk into Pig will have a specific schema and structure. Pig needs to understand the structure so the data can automatically go through a mapping when you do the loading.
Fortunately, the Pig data model is rich enough for you to manage most of what's thrown in its way like table-like structures and nested hierarchical data structures. However, Pig data types can be divided into two groups in general terms: scalar forms and complex types. Scalar types contain a single value, while complex types include other values, such as the values of Tuple, Container, and Map below.
In its data model, Pig Latin has those four types
Atom:
An atom is any single attribute, like, for example, a string or a number — 'Diego' The atomic values of Pig are scalar forms that appear, for example, in most programming languages — int, long, float, double, char array and byte array.
Tuple:
A tuple is a record generated by a series of fields. For example, each field can be of any form — 'Diego,' 'Gomez,' or 6). Just think of a tuple in a table as a row.
Bag:
A pocket is a set of tuples, which are not special. The bag's schema is flexible — each tuple in the set can contain an arbitrary number of fields, and can be of any sort.
Map:
A map is a set of pairs with main values. The value can store any type, and the key needs to be unique. A char array must be the key of a map, and the value may be of any kind.
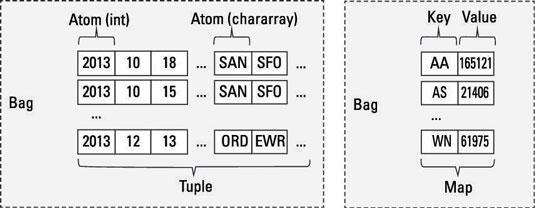
The figure also offers some fine examples of data types Tuple, Container, and Map.
Also the value of all these forms may be null. The null semance is similar to those used in SQL. In Pig 's notion of null means the value is unknown. In cases where values are unreadable or unrecognizable, nulls can show up in the data — for example, if you were using a wrong data form in the LOAD statement.
Null
Null may be used as a placeholder before data has been added, or as an optional value for a sector.
Pig Latin has a simple syntax of strong semics that you will be using to perform two primary operations.
Data access
Transform
Accessing data in a Hadoop sense means allowing developers to load, store, and stream data, while transforming data means profiting from Pig's ability to group, enter, merge, break, filter, and sort data. The next paragraph provides an overview of the relevant operators for each operation.
Latin Pig Operators
Explanation of service by operator
LOAD / STORE
Data Access Read and write data to file system
DUMP
Write to default output (stdout)
STREAM
All records are sent via external binary
FOREACH Transformations
Use expression for each record and output, one or more
Documents FILTER
Submit predicting and deleting records that do not reach
Contract GROUP / COGROUP
Files records from one or more with the same key
Returns
Enter Join two or more records according to a condition
CROSS
Cartesian product of two inputs or more
ORDER
Sort key baseline records
DISTINCT
Duplicate documents removed
UNION
Merge 2 data sets
SPLIT
Divide the data into two or more predicate dependent bags
LIMIT
subdivides record number
Pig also offers a few operators to support debug and troubleshoot, as shown.
To debug and troubleshoot operators
Definition of operator's activity
Debug
Explain Give back the scheme of a partnership.
DUMP
Dump the contents of a screen connection.
EXPLAIN
View plans for execution with MapReduce.
Part of Hadoop's paradigm change is that you apply your scheme at Read rather than Load. When you load data into your database system, you must load it into a well-defined set of tables according to the old way of doing things — the RDBMS way. Hadoop lets you store up front all the raw data and apply the Read scheme.
With Pig, you do this with the aid of the LOAD operator, during data loading.
The optional Usage statement defines how to map the data structure inside the file to the Pig data model — in this case, the data structure of PigStorage), (which parses delimited text files. (This section of the USING declaration is often referred to as LOAD Func and functions like a custom deserializer)
The optional AS clause sets out a schema for the mapped data. If you are not using an AS clause, you are basically telling the default LOAD Func to expect a plain text file delimited by tab. Without a schema, the fields must be referenced by location, since no name is specified.
Using AS clauses ensures you have a read-time schema in place for your text files, allowing users to get started quickly and offering agile schema modeling and versatility so you can add more data to your analytics.
Load operator
The LOAD operator works on the lazy assessment principle, often referred to as call-by-need. Now lazy doesn't sound particularly praiseworthy, but all it does is postpone an expression evaluation until you really need it.
In the Pig example context, that means that no data is transferred after the LOAD statement is executed — nothing gets shunted around — until a statement is found to write data. You can have a Pig script that is a page loaded with complex transformations, but until the DUMP or STORE statement is found nothing will be executed.
Conclusion
I hope you reach to a conclusion about Pig latin data types. You can learn more through big data hadoop training