Basics of Apache Spark Tutorial
In this lesson, you will learn about the basics of Spark, which is a component of the Hadoop ecosystem. Let us look at the objectives of this Spark Tutorial for beginners.
Objectives
After completing this lesson, you will be able to:
Describe the limitations of MapReduce in Hadoop
Compare batch and real-time analytics
Explain Spark, its architecture, and its advantages
Understand RRD Operations
Compare the Spark Hadoop ecosystem with the MapReduce ecosystem
Understand the functional programming in Spark
Let us now look at the history of Spark, and its needs, components, and advantages.
History of Spark
Spark as a data processing framework was developed at UC Berkeley’s AMPLab by Matei Zaharia in 2009.
In 2010, it became an open-source project under a Berkeley Software Distribution license. In the year 2013, the project was donated to the Apache Software Foundation, and the license was changed to Apache 2.0.
In February 2014, Spark became an Apache Top-Level Project. By November 2014, Spark was used by the engineering team at Databricks, a company founded by the creators of Apache Spark to set a world record in large-scale sorting.
Now Databricks provides commercial support and certification for taking the Spark programming test. At present, Spark exists as a next-generation real-time and batch processing framework.
Let’s try to understand what batch and real-time processing mean.
Batch vs. real-time processing
Batch processing and real-time processing differences are explained in the table given below.
Batch processing
|
Real-time processing
|
A large amount of data or transactions are processed in a single run over a period.
The associated jobs generally run entirely without any manual intervention.
The entire data is pre-selected and fed using command-line parameters and scripts.
In typical cases, batch processing is used to execute multiple operations, handle heavy data load, generate reports, and manage data workflow which is offline.
An example is to create daily or hourly reports for decision making.
|
It occurs instantaneously on data entry or command receipt.
It needs to execute within stringent response time constraints.
An example is fraud detection.
|
Let us look at the Limitations of MapReduce in Hadoop in the next section of this Apache Spark Tutorial.
Limitations of MapReduce in Hadoop
The need for Spark was created by the limitations of MapReduce, which is another data processing framework in Hadoop. Let’s see what these limitations are.
Unsuitable for real-time processing
MapReduce is suitable for batch processing, where data is processed as a periodic job. Thus, it takes time to process data and provide results if the data is high.
Depending on the amount of data and the number of nodes in the cluster to complete a job, it just takes minutes to process the data. However, it is not a good choice for real-time processing.
Unsuitable for trivial operations
MapReduce is also not suitable for writing trivial operations such as Filter and Join. To write such operations, you might need to rewrite the jobs using the MapReduce framework, which becomes complex because of the key-value pattern.
This pattern is required to be followed in reducer and mapper codes.
Unfit for large data on the network
MapReduce doesn’t work well with large data on a network. The reason is that it takes a lot of time to copy the data, which may cause bandwidth issues. It works on the data locality principle and hence works well on the node where the data resides.
Unsuitable with OLTP
MapReduce is also unsuitable for Online Transaction Processing or OLTP that includes a large number of short transactions. Since it works on the batch-oriented framework, it lacks latency of seconds or sub-seconds.
Unfit for processing graphs
MapReduce is unfit for processing graphs. Graphs represent the structures to explore relationships between various points, for example, finding common friends in Social Media like Facebook.
Hadoop has the Apache Giraph library for such cases; it runs on the top of MapReduce and adds to the complexity.
Unfit for iterative execution
Another important limitation is its unsuitability for iterative program execution. Some use cases, like K-means, need such execution where data needs to be processed again and again to refine results. MapReduce runs from the start every time as it is a state-less executor.
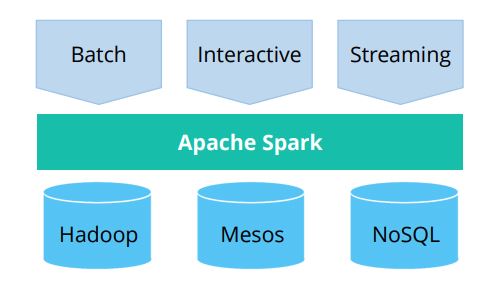
Introduction to Apache Spark
Spark is an open-source cluster-computing framework which addresses all the limitations of MapReduce.
It is suitable for real-time processing, trivial operations, and processing larger data on the network. It is also suitable for OLTP, graphs, and iterative execution.
As compared to the disk-based, two-stage MapReduce of Hadoop, Spark provides up to 100 times faster performance for a few applications with in-memory primitives.
Fast performance makes it suitable for machine learning algorithms as it allows programs to load data into the memory of a cluster and query the data constantly.
Let’s discuss the components of Spark.
Components of a Spark Project
A Spark project comprises various components such as:
Let us now talk about each component in detail.
Spark Core and RDDs
Spark Core and RDDs are the foundation of the entire Spark project. They provide basic Input/Output functionalities, distributed task dispatching, and scheduling.
RDDs are the basic programming abstraction and are a collection of data that is partitioned across machines logically. RDDs can be created by applying coarse-grained transformations on the existing RDDs or by referencing external datasets.
The examples of these transformations are reduced, join, filter, and map.
The abstraction of RDDs is exposed similarly as in-process and local collections through a language-integrated Application Programming Interface or API in Python, Java, and Scala.
As a result, the RDD abstraction, the complexity of programming is simplified, as the manner in which applications change RDDs is similar to changing local data collections.
Spark SQL
Spark SQL resides at the top of Spark Core. It introduces SchemaRDD, which is a new data abstraction and supports semi-structured and structured data.
SchemaRDD can be manipulated in any of the provided domain-specific such as Java, Scala, and Python by the Spark SQL. Spark SQL also supports SQL with Open Database Connectivity or Java Database Connectivity, commonly known as ODBC or JDBC server and command-line interfaces.
Spark Streaming
Spark Streaming leverages the fast scheduling capability of Spark Core for streaming analytics, ingesting data in small batches, and performing RDD transformations on them.
With this design, the same application code set written for batch analytics can be used on a single engine for streaming analytics.
Machine Learning Library
Machine Learning Library, also known as MLlib lies on top of Spark and is a distributed machine learning framework.
MLlib applies various common statistical and machine learning algorithms. With its memory-based architecture, it is nine times faster than the Apache Mahout Hadoop disk-based version.
Also, the library performs even better than Vowpal Wabbit or VW. The VW project is a fast out-of-core learning system sponsored by Microsoft.
GraphX
GraphX also lies on the top of Spark and is a distributed graph processing framework. For the computation of graphs, it provides an API and an optimized runtime for the Pregel abstraction.
Pregel is a system for large-scale graph processing. The API can also model the Pregel abstraction. We discussed earlier that Spark provides up to 100 times faster performance for a few applications with in-memory primitives.
In the next section, let’s discuss the application of in-memory processing using column-centric databases.
Application of In-Memory Processing
In column-centric databases, similar information can be stored together and hence data can be stored with more compression and efficiency.
The working of in-memory processing can be explained as follows:
In an in-memory database, the entire information is loaded into memory, eliminating the need for indexes, aggregates, optimized databases, star schemas, and cubes.
With the use of in-memory tools, compression algorithms can be implemented that decrease the in-memory size, even beyond what is required for hard disks. Users querying data loaded in memory is different from caching.
In-memory processing also helps to avoid performance bottlenecks and slow database access. Caching is a popular method for speeding up the performance of a query, where caches are subsets of very particular organized data, which are already defined.
With in-memory tools, data analysis can be flexible in size and can be accessed within seconds by concurrent users with an excellent analytics potential. This is possible as data lies completely in-memory. In theoretical terms, this leads to data access improvement that is 10,000 to 1,000,000 times fast, when compared to a disk.
It also reduces the performance tuning needed by IT professionals and therefore provides faster data access for end users.
With in-memory processing, it is also possible to access visually rich dashboards and existing data sources. This ability is provided by several vendors.
In-memory processing allows end users and business analytics to create customized queries and reports without any need of extensive expertise or training.
In the next section, let us understand what Language Flexibility in Spark is.
Language Flexibility in Spark
We have already discussed that Spark provides performance, which in turn provides developers a rewarding experience.
Spark is chosen over MapReduce, mainly for its performance advantages and versatility. Apart from this, another critical advantage is its development experience along with language flexibility.
Spark provides support to various development languages like Java, Scala, and Python and will likely support R as well. Also, Spark has the capability to define functions inline.
With the temporary exception of Java, a common element in these languages is that they provide methods to express operations using lambda functions and closures.
Using lambda closures, you can use the application core logic to define the functions inline, which helps to create easy-to-comprehend codes and preserve application flow.
Let’s look at MapReduce in a Hadoop ecosystem.
Hadoop ecosystem vs. Spark
Let us compare the main features of MapReduce in a Hadoop ecosystem and Apache Spark
Hadoop ecosystem
|
Apache Spark
|
|
|
|
You can perform every type of data processing using Spark that you execute in Hadoop.
For batch processing, Spark batch can be used over Hadoop MapReduce.
For Structured Data Analysis, Spark SQL can be used using SQL.
For Machine Learning Analysis, the Machine Learning Library can be used for clustering, recommendation, and classification.
For Interactive SQL Analysis, Spark SQL can be used instead of Impala.
Also, for real-time Streaming Data Analysis, Spark streaming can be used in place of a specialized library like Storm.
Spark - Advantages
Spark has three main advantages which are:
Provide Speed capability
Combines the various processing types
Supports Hadoop.
Speed
The feature of speed is critical to process large datasets, as this implies the difference between waiting for hours or minutes and exploring the data interactively.
Spark has extended the MapReduce model to support computations like stream processing and interactive queries, supporting run computations in memory concerning speed.
Also, its related system is more effective when compared to MapReduce to run complex applications on a disk. This adds to the speed capability of Spark.
Combination
Spark covers various workloads that require different distributed systems such as streaming, iterative algorithms, and batch applications. As these workloads are supported on the same engine, combining different processing types is easy.
Spark is normally required in the production of data analysis pipelines. The combination feature also allows easy management of separate tools.
Hadoop Support
Spark is capable of creating distributed datasets from any file that is stored in the Hadoop Distributed File System or any other supported storage systems. You must note that Spark does not need Hadoop.
It supports the storage systems that implement the APIs of Hadoop, and Sequence Files, Parquet, Avro, text files, and all other Input/Output formats of Hadoop. Unification not only provides developers with the advantage of learning only one platform but also allows users to take their apps everywhere.
The graph shown below shows the apps and systems that can be combined with Spark.
Other advantages of Spark are:
A Spark project includes various closely-integrated components for distributing, scheduling, and monitoring applications with many computational tasks across a computing cluster or various worker machines.
The Spark’s core engine is general purpose and fast. As a result, it empowers various higher-level components that are specialized for different workloads like machine learning or SQL. These components can interoperate closely.
It integrates tightly, allowing you to create applications that easily combine different processing models. An example is the ability to write an application using machine learning to categorize data in real time as it is ingested from sources of streaming.
It allows analysts to query the data which results through SQL. Moreover, data scientists and engineers can access the same data through the Python shell for ad-hoc analysis and in standalone batch applications. For all this, the IT team needs to maintain one system only.
Let’s now understand the components of the Spark architecture.
Spark - Architecture
The components of the Spark execution architecture are:
- Spark-submit script
- Spark applications
- Cluster managers
- Spark’s EC2 launch scripts
The components of the Spark execution architecture are explained below:
Spark-submit script
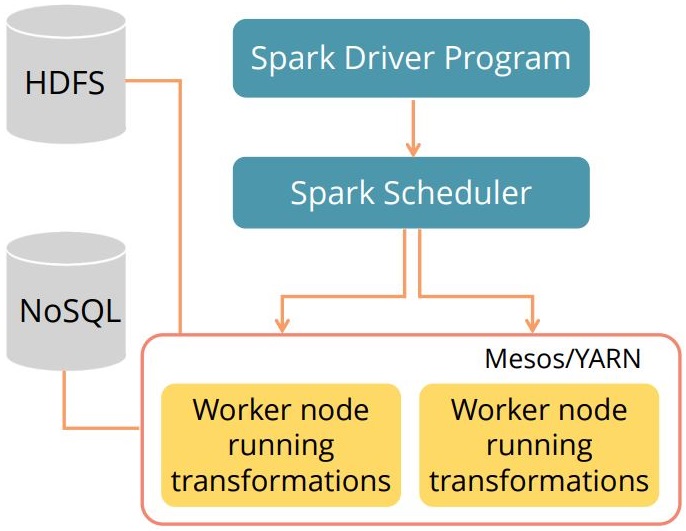
Spark architecture comprises a Spark-submit script that is used to launch applications on a Spark cluster.
The Spark-submit script can use all cluster managers supported by Spark using an even interface. As a result, you need not configure your application for each one specifically.
Spark applications
Spark applications run independently as a set of processes on a Spark cluster. These are coordinated by the SparkContext object in the driver program, which is your main program.
Cluster managers
SparkContext can connect to different cluster managers, which are of three types: ‘Standalone, Apache Mesos, and Hadoop YARN.
A standalone cluster manager is a simple one that makes setting up a cluster easy.
Apache Mesos is a general cluster manager that is also capable of running service applications and MapReduce.
Hadoop YARN is the resource manager in Hadoop
Spark’s EC2 launch scripts
The Spark’s EC2 launch scripts ease the launch of a standalone cluster on Amazon EC2.
The interaction of these components is shown in the diagram.
Let us now look at the Spark Execution Architecture.
Spark Execution Architecture
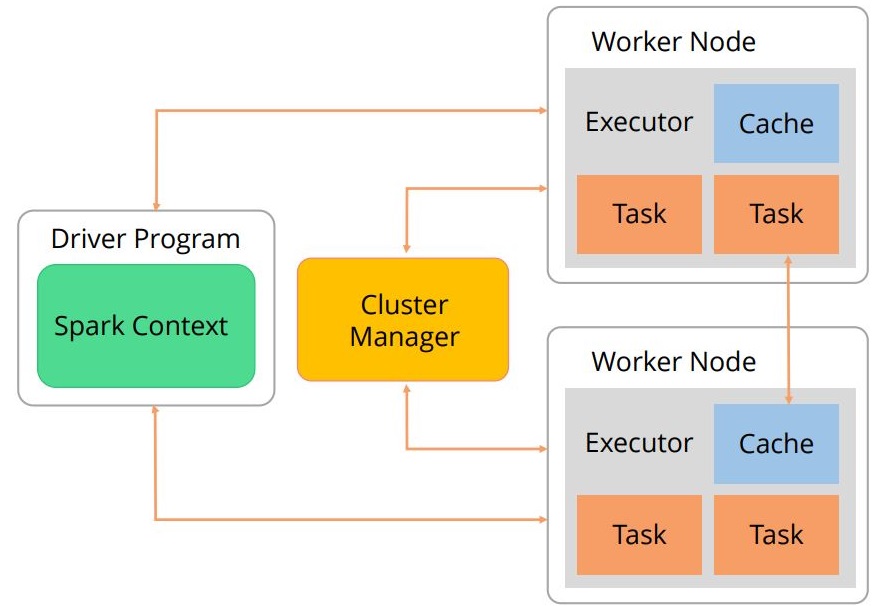
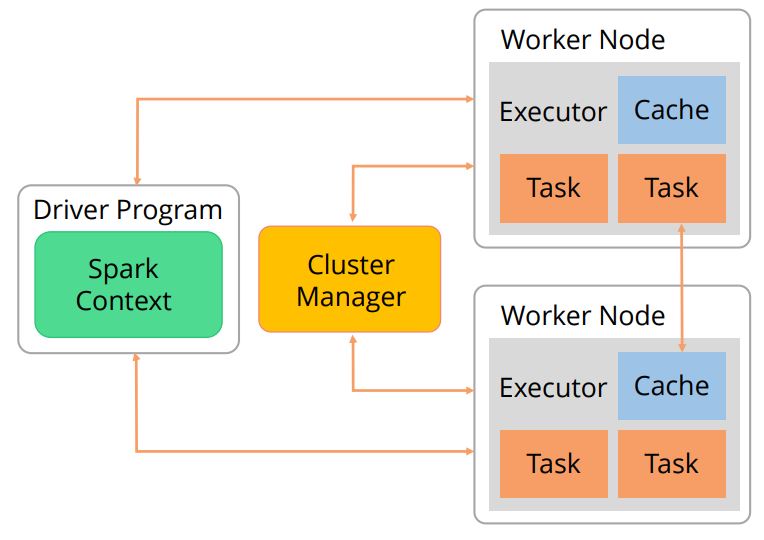
The SparkContext connects to the cluster managers. We discussed earlier that the three types of Cluster managers are Standalone, Apache Mesos, and Hadoop YARN. The cluster manager allocates resources across applications.
The diagram given below shows the process of Spark execution.
Once the SparkContext is connected to the cluster manager, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application.
Next, it sends your application code to the executors. Finally, SparkContext sends tasks to the executors to run.
Let’s now talk about the automatic parallelization of complex flows in Spark.
Spark Execution - Automatic Parallelization
Spark execution is explained through the points below.
It is your task to make the sequence of MapReduce jobs parallel in case of a complex pipeline. Here, a scheduler tool like Oozie is generally required for constructing this sequence carefully.
Using Spark, the series of individual tasks is expressed regarding a program flow. To give a complete picture of the execution graph to the system, this flow is lazily evaluated.
In lazy evaluation, the operations are only executed in the end. Using this approach, the core scheduler can map the dependencies lying between various application stages correctly.
This allows parallelizing the operators flow automatically without any intervention.
With automatic parallelizing capability, you can also achieve a few optimizations to the engine with less burden.
How automatic parallelization works can be explained in the given diagram.
Running Spark in Different Modes
The different deployment modes of Spark are listed below.
Spark as Standalone:
The standalone mode is a simple one that can be launched manually, by using launch scripts or by starting a master and workers. This mode is usually used for development and testing.
Spark on Mesos:
Spark can also be run on hardware clusters that are managed by Mesos. Running Spark in this mode has advantages like scalable partitioning among different Spark instances and dynamic partitioning between Spark and other frameworks.
Spark on YARN:
Running Spark on YARN runs parallel processing and avails all benefits of the Hadoop cluster.
Spark on EC2:
By running Spark on EC2, you will receive the key-value pair benefits of Amazon.
Spark - Use Cases
Companies like NTT DATA, Yahoo, GROUPON, NASA, Nokia, and others are using Spark for creating applications for different use cases.
These use cases are given to the network machine data which performs Big Data analytics for subscriber personalization in the telecommunications domain.
It executes the Big Data Content platform, which is a B2B content asset management service that provides an aggregated and searchable source of public domain media, live news feeds, and archives of content.
A few more use cases are building data intelligence and e-Commerce solutions in the retail industry, and analyzing and visualizing patterns in large-scale recordings of brain activities.
Let us discuss some of the important concepts of Spark, such as Spark-Shell and SparkContext in the next section.
Spark-Shell
The Spark-Shell provides interactive data exploration. It helps in prototyping an operation quickly instead of developing a full program. It is available in Python and Scala.
You can access the Python Spark-Shell using pyspark and Scala Spark-Shell using spark-shell.
SparkContext
SparkContext is the main entry point of Spark API. Every Spark application requires a SparkContext. Spark-Shell provides a preconfigured SparkContext called “sc.”
You can view, through spark-shell and also through pyspark as shown in the diagrams given below.
In the next section, we will learn more about Resilient Distributed Datasets or RDDs, which is a Spark component. We will also learn how an RDD is created from a file and get introduced to RDD operations, Lazy evaluation, RDD lineage, and pipelining.
Resilient Distributed Datasets(RDDs) and its Operation
Most Spark programming consists of performing operations on RDDs, where ‚ means data in memory can be recreated if it is lost.
“Distributed”‚ means processed across the cluster while ‚“dataset”‚ is initial data that can come from a file or can be created programmatically.
RDDs are the fundamental unit of data in Spark. Most Spark programming consists of performing operations on RDDs.
There are three ways to create an RDD which are:
Let’s discuss how to create an RDD from a file.
How to Create an RDD from a File
The example below shows how the file, simplilearn.txt is distributed across multiple worker nodes.
The first line of code creates an RDD named ‚“mydata.
scala> val mydata =
sc.textFile("simplilearn.txt")
The second line of code counts the number of lines present in,“mydata”‚ RDD using the count function. The output is four.
scala> mydata.count
16/08/10 06:10:41 INFO
scheduler.DAGScheduler: Job 0 finished:
count at <console>:24, took 1.010566 s
res0: Long = 4
Let us look at the types of RDD operations in the next section.
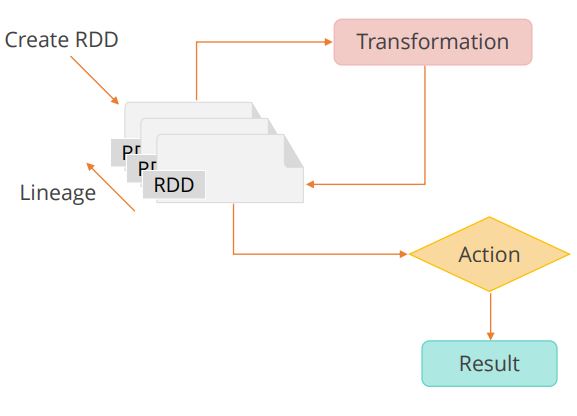
RDD Operations
RDDs provide support to two different types of operations, which are ‚“actions”‚ and “transformations.” These operations are shown in the diagram given below.
As explained in the diagram above, Actions allow returning a value to the driver program once a computation on the dataset is run. Transformations allow the creation of another dataset from an existing one.
Let’s look at each operation type closely.
RDD Operations - Action
On the table in this section, some common actions available in Scala and Python are listed.
Common Actions
|
count()
|
Returns the number of elements
|
take()
|
Returns an array of the first N elements
|
collect()
|
Returns an array of all elements
|
saveAsTextFile(file)
|
Saves RDD to text file
|
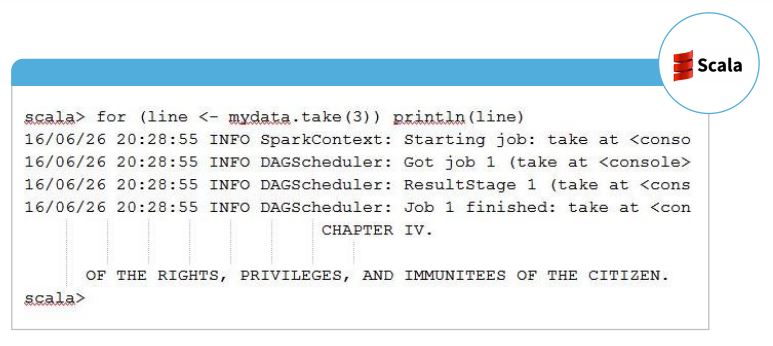
The image shown below shows RDD Operations - Action using Scala.
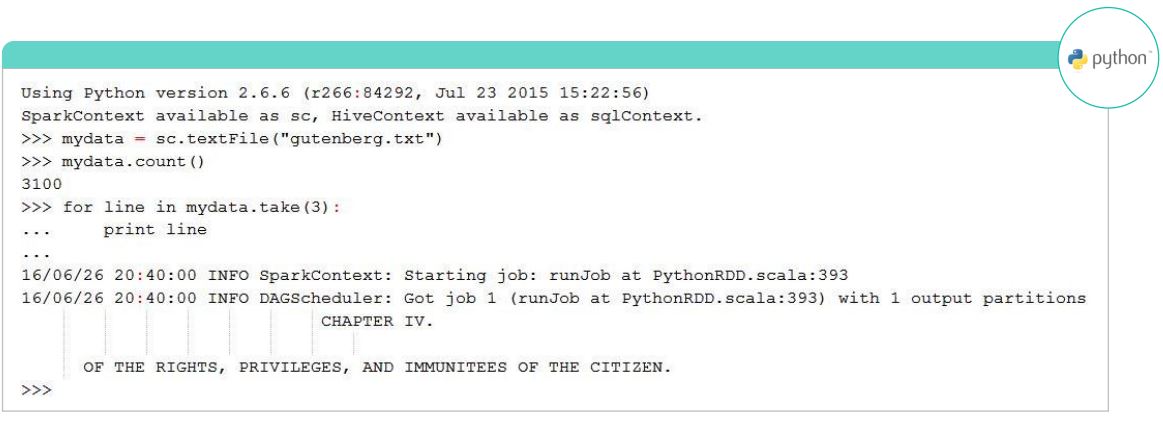
The image shown below shows DD Operations - Action using Python.
RDD Operations - Transformation
RDDs are immutable. Data in an RDD never changes; they transform in sequence to modify the data as needed. You don’t need to make changes to an RDD; you can simply create a new RDD using a transformation. Spark programs are mostly made up of a series of transformations.
There are two common transformations, Map and filter functions.
Example - Map and Filter Transformation
The example below shows you how each code returns the same result in two successive transformations in Python and Scala.
Using Python:
Using Scala:
The result of this map and filter transformation in python and scala is shown below.
The first code maps each original line by converting the string to upper case and the second code alters outlines which do not start with the letter “I.”
Let us now understand the Lazy evaluation in Spark and its steps.
Lazy Evaluation Steps
Lazy evaluation improves the use of disk and memory in Spark. Until the execution of the Action operation, the file is not even read. Let’s understand Lazy Evaluation works with the example given below.
Let us now understand the steps for the same example.
Step 01
The first step starts with a text file. The example shown above is simplilearn.txt. The only step that happens at this stage is that lazy evaluation creates the variable for the RDD and links it to the file, but it doesn’t read the file.
Step 02
It transforms the base RDD to upper case. Here, lazy evaluation creates an empty RDD and links it to its parent; however, it still doesn't process it. The file still hasn’t been read.
Step 03
It alters the upper case RDD for lines beginning with “I.” The lineage continues to grow.
Step 04
The fourth step is called as the action step. “Count” is an action, which means that it processes the data in the RDD and returns a value to the calling program.
At the time when the operation is performed on the last RDD, Spark recursively processes each RDD and its parent. The important point to note here is that nothing happens until that final call or action is taken.
Since the data is only processed at the end during the action step, it is termed Lazy evaluation. Therefore, each command line is considered separate from the one above it.
The RDDs stay populated after the call, which isn’t the case in this example. They get evaluated only when the script reaches the action. You would have noticed in the previous example that the output of each transformation was assigned to a new variable.
Let us now look at the chaining transformation
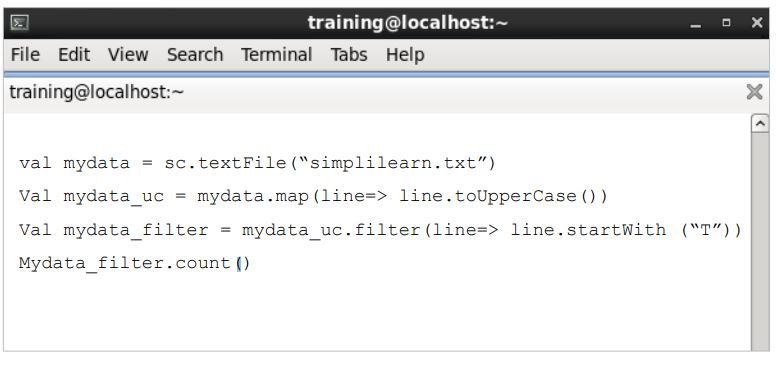
Chaining Transformations
Chains the calls together without any reference to the intermediate datasets. This has no impact on the result, as it is a syntactical difference.
On this section you will notice that by chaining transformations, you get the same results like as in the preceding code.
val mydata = sc.textFile(“simplilearn.txt”)
Val mydata_uc = mydata.map(line=> line.toUpperCase())
Val mydata_filter = mydata_uc.filter(line=> line.startsWith (“T”))
Mydata_filter.count()
This Is exactly equivalent to -
Sc.textFile(“simplilearn.txt”).map(line=> line.toUpperCase())
.filetr(line=> line.startswith (“T”)).count()
You can’t chain a transformation after an action because the output of the actions are values, not RDDs.
The last operation in this example is an action that will trigger the lazy evaluation, but you can’t extend the chain further because the output of count is an integer.
Please note that an RDD is still created for each of these transformations, even if there are no variables pointing to the RDD. Spark maintains a big table of all RDDs.
You saw this example in the Scala version. In the Python version, it appears as below.
val mydata = sc.textFile(“simplilearn.txt”)
Val mydata_uc = mydata.map(lambda s: s.upper())
Val mydata_filter = mydata_uc.filter(lambda s:s.startswith (“T”))
Mydata_filter.count()
This Is exactly equivalent to -
Sc.textFile(“simplilearn.txt”).map(lambda s: s.upper())
.filetr(lambda s:s.startswith (“T”)).count()
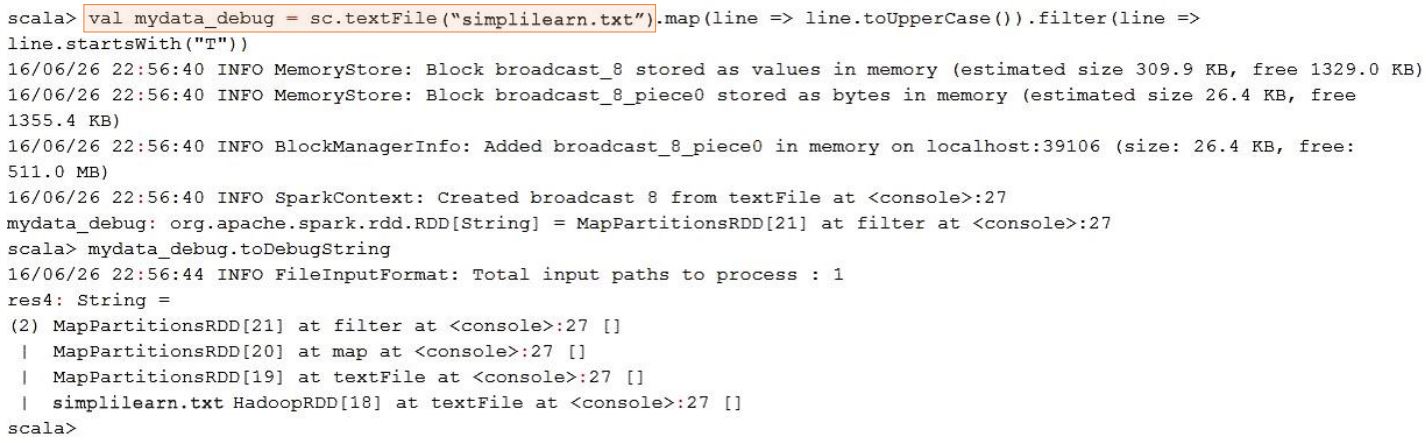
RDD Lineage from the Stack - Scala
Spark maintains each RDD’s lineage, that is, the previous RDDs on which it depends. You can use the toDebugString command to view the lineage of an RDD. You can also see on the section that the RDD is created by typing val maydata_debug = sc.textFile. This is called the Scala version.
RDD Lineage from the Stack - Python
The Python version of the same file is shown in the image below.
“toDebugString()‚always returns a single string containing multiple lines, delineated by new-line characters. The Scala shell will automatically display these on separate lines.
On the other hand, the Python shell will display newlines as “n, and the Python print function will convert them to actual new lines.
You may notice that the Scala and Python output for “toDebugString() isn't identical, even after improvisation. This reflects underlying differences between the implementation of Spark in Python and Scala.
Note that the Python lineage shows three RDDs in the lineage and the Scala lineage shows four, including two rather than one MappedRDD. This is because of how sc.textFile is implemented in Scala.
In Scala, the output of text File is a MappedRDD which depends on a HadoopRDD, whereas in Python the output is HadoopRDD.
Pipelining
Spark performs the sequence of transformations row-wise since it does not store data. This concept is called pipelining. Let’s understand it through an example.
You can see that the file simplilearn.txt is brought into spark memory using sc.textFile.
On the next the section, you can see that the whole file is not being processed; instead, it starts with only the first row.
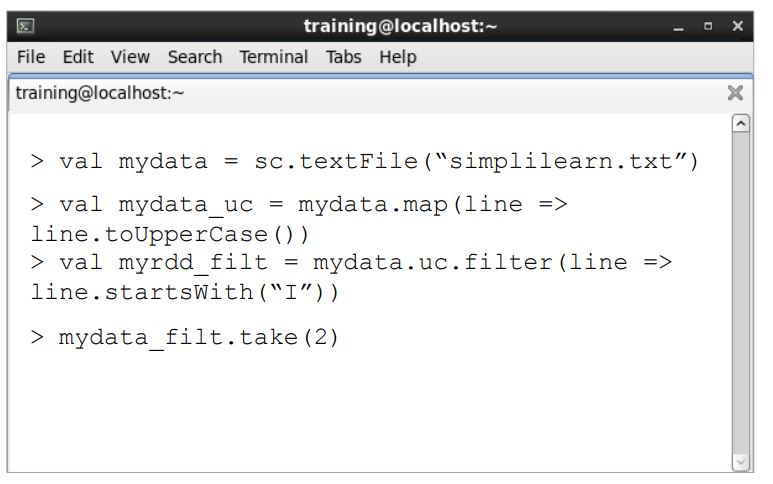
Now, let’s perform the “toUppercase transformation on the first row of the simplilearn.txt file. You can see that the first row is now in upper case. After the “toUpperCase” transformation, let’s perform the other transformation “startsWith”.
You can see in the image that the transformation has been executed in the first row. Now, the action (take) will print this line.
Similarly, all the above steps will be executed for the second, third, and the fourth row, one after the other. Since the second and third rows are being filtered in mydata_filtrdd, the take(2) action will print the second and third lines. Both the lines start with the letter“I.”
Now, there will be no further processing required on the fourth row because two rows are now printed as required by the take(2) action.
Let us now look at the functional programming in spark in the next section of this tutorial.
Functional Programming in Spark
Spark depends heavily on the concepts of functional programming. Functions are the fundamental units of programming. They contain input and output only without any state or side effects.
Key Concepts in Functional Programming
The key concepts in the functional programming of Spark include passing functions as input to other functions. This is done using Anonymous functions.
The lambda operator or lambda function is a way to create small anonymous functions, that is, functions without a name. These functions are specific functions, that is, they are needed only where they have been created.
Lambda functions are mainly used in combination with the functions such as filter (), map (), and reduce ().
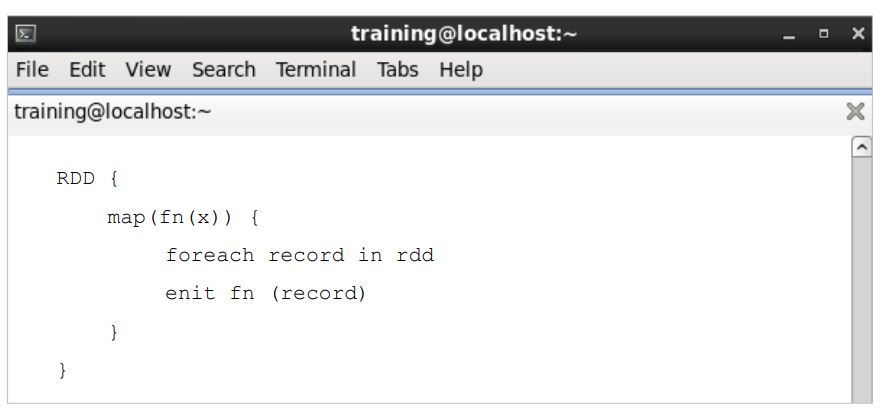
RDD Map Operation
The section below shows you how a typical Spark function, in this case, map, is implemented.
Here, a function as a parameter is being executed sequentially over a series of data.
Passing Named Functions
The section below shows how named functions are passed using python and scala.
In this example, we define a function which takes a single parameter. You can use a shortcut to pass the function to the “map” transformation and just pass the name of the function since it is taking a single parameter.
Then Spark will call the function for each item in the RDD, passing the item to the function. This explains passing named function. Both these examples shown on section give the same result.
Here, you are defining your function, which returns a string converted to upper case. You would have also observed that you can define your own named function and pass that instead of passing s.upper().
Anonymous Functions
Spark doesn’t necessarily need anonymous functions. You can define and name each function separately, but that would make the code cumbersome. That’s why Anonymous functions are used extensively in Spark, even though they are not specically a Spark concept.
Java 7 does not support Anonymous functions, and there is no Spark-Shell for Java. This is why the course is taught in Python or Scala.
The newly released Java 8 includes anonymous functions using the greater than the operator. Java 8 support was added to Spark in 1.0.
Note that the lambda syntax, used to create anonymous functions in Python is beyond the scope of this course. However, if you are new to the concept, you are encouraged to read about it in the Python documentation or closure syntax in Scala.
Passing Anonymous Functions
The code on the below section does the same as the toUpper() example in the previous section, but instead of defning the function separately and giving it a name, we define the function inline.
It doesn’t have a name and is, therefore, called an anonymous function.
These are also called lambda functions or closures. Scala provides a shortcut for referencing the value passed to an anonymous function. The use of the underscore is frequently used in the Spark code but not used here as it makes the code less understandable.
The use can also be confusing as you can’t reference the same variable twice. For example, a second underscore refers to a second parameter and so on. Also, you can only use the underscore in the outermost scope.
There is a big difference between the syntax for Scala closures and lambda functions in Python. In Scala, you can have arbitrarily complex functions that span multiple lines. Whereas, in Python, lambda functions can confine in a single line.
Scala closures can defne locally-scoped variables, as well as have side effects. This is not possible in Python. It becomes apparent in Spark when you look at all the example codes, which often includes long, complex anonymous functions.
Summary
Now let’s summarize what we learned in this spark tutorial for beginners.
Apache Spark is a fast, general engine for large-scale data processing.
RDDs are the fundamental units of data in Spark.
Parallelize an existing collection or reference an external dataset to create RDDs.
Actions and transformation are two types of RDD operations. You can either pass name functions or make them anonymous.
Conclusion
This concludes the lesson on Basics of Apache Spark.