In this article let us see about big data Hadoop admin and Hadoop architecture. Big data is a concept defined by Structured & Unstructured for a large amount of data. Structured data refers to highly structured data such as in a Relational Hadoop Database(RDBMS) where information is stored in tables.
Structured data can be quickly searched by the end user or search engine. In comparison, unstructured data doesn't fit into conventional RDBMS rows & columns. Types of unstructured data include email, images, audio files, web sites, social media posts, etc. let us see about big data characteristics,More info go through hadoop administration course
Big Data characteristics
Big Data characteristics can be described by the following characteristics
● Volume: The volume of data in big data matters. You're going to work with massive quantities of unstructured data which are small in quality. Data volumes can vary from Terabytes to Petabytes. Scale defines whether the data can be considered as Big Data or Not.
● Velocity: It is the speed at which data is obtained and processed. Big Data is also in real time.
● Variety: It refers to several types of data, both structured and unstructured i.e. Audio, video,
pictures, text messages. This helps to create a concrete result for a person who analyzes big
data.
● Veracity: refers to data quality of the information collected which affects the accuracy of the
analysis.
Wide collection of data sets which can not be stored on a single computer. Big data is huge volume,
rapid pace, and numerous information assets needing an creative framework for enhanced insights and
decision-making.
Big Data (Big Data) & Solution (Hadoop)
Big Data is huge data above the petabyte that is poorly or less organized. This data can not be
completely understood by a person.
Hadoop is the most common Big Data platform on demand that solves Big Data issues.
Here is the Apache Software Foundation's timeline for Hadoop
What is Hadoop?
Hadoop is an open-source platform that allows large data to be stored and processed through simple
programming models in a distributed environment through computer clusters.
Hadoop is designed to scale up to thousands of machines from single servers, each providing local
computing and storage.
Hadoop Architecture Components
Hadoop architecture has three main components:
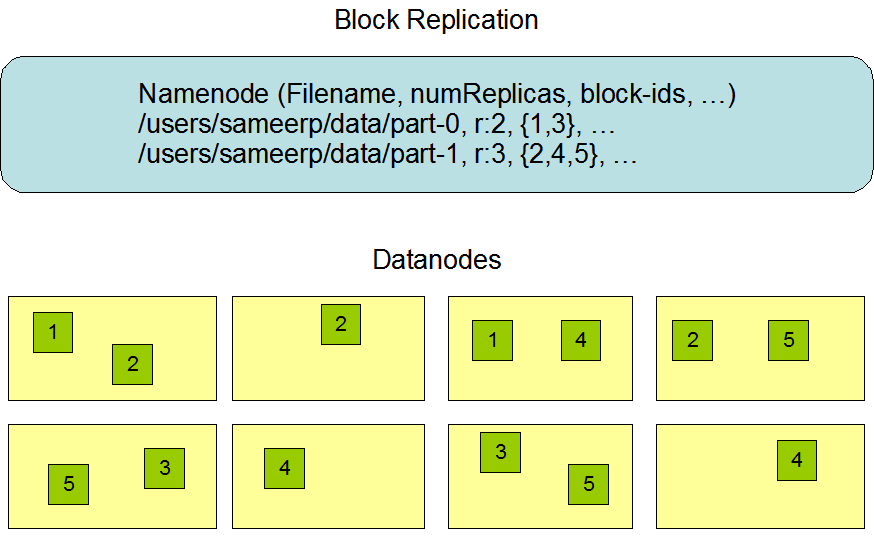
● Hadoop Distributed File System (HDFS),
● Hadoop MapReduce and
● Hadoop Yarn
A) Data Storage: Hadoop Distributed File System (HDFS):
It is a distributed file system offering high-throughput access to data from applications.
B) Data Processing-Hadoop MapReduce:
This is a YARN-based framework for massive dataset parallel processing. In fact, the term MapReduce refers to the following two separate tasks performed by Hadoop programs: the Map Task: this is the first task to take input data and transform it into a collection of data where individual elements are split into tuples (key / value pairs).
The Reduce Task:
This function takes the results as input from a map function and combines certain data tuples into a
smaller collection of tuples. The reduction function is often carried out after the map function
C) Scheduling & Resource Management- > Hadoop YARN: It is a system for job scheduling and management of cluster resources.
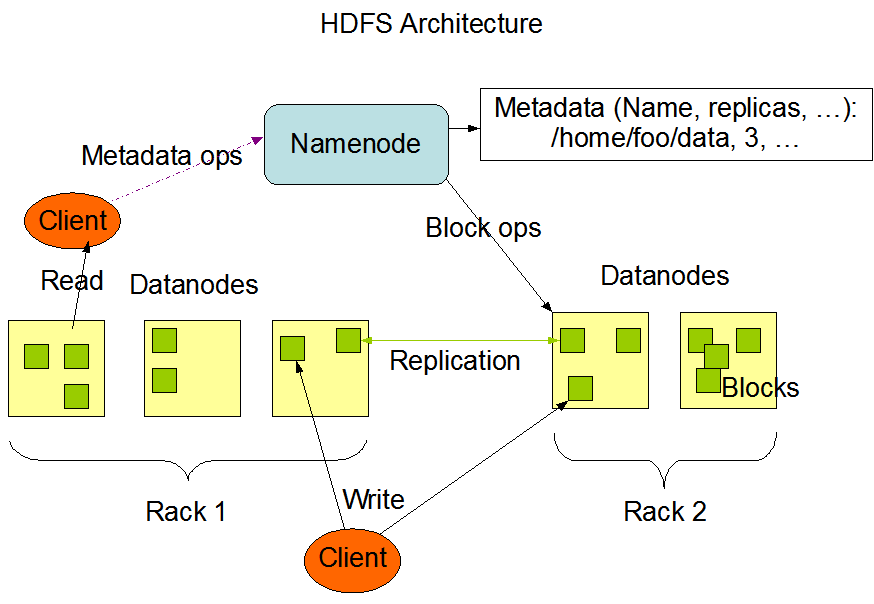
HDFS Architecture
HDFS Architecture Name Node and Data Node are the principal components of HDFS.
Name Node in Hadoop architecture
The Name nodes are maintained and operated by the master daemon. This records all the files
contained in the cluster metadata, e.g. location of the contained blocks, file size, permissions, hierarchy,
etc. The data itself is stored on Data Nodes. We are responsible for helping clients read and writing
messages. They are also responsible for block formation, block deletion and replication, based on the
Name Node decisions.
Data Node in Hadoop architecture
Data Node controls the status of an HDFS node and communicates with blocks. DataNode can perform
CPU-intensive tasks such as semantic and language analysis, statistics and machine learning tasks, and I /O-intensive tasks such as clustering, data import, data export, search, decompression and indexation.
For data processing and conversion a Data Node requires a lot of I / Os.
Each Data Node connects to the Name Node upon startup and performs a handshake to verify the
DataNode's namespace ID and software version. If either of them fails, the Data Node must immediately shut down. A Data Node verifies the possession of block replicas by submitting a block report to the Name Node. The first block report will be submitted, as soon as the Data Node registers. Data Node sends a heartbeat to the Name Node every 3 seconds to confirm the operation of the DataNode and the replicas of the block it hosts.
MapReduce in Hadoop Architecture Implementation
The essence of Hadoop's distributed computing platform is its Hadoop MapReduce programming model based on java. Map or Reduce is a particular form of guided acyclic graph that can be applied to a wide variety of cases of business use. Map function converts the piece of data into pairs of key-value and then the keys are sorted where a reduction function is applied to combine the key-based values into a single output.
Hadoop MapReduce
The execution of a MapReduce job begins when the client submits to the Job Tracker the work
configuration defining the map, combining and reducing functions together with the location for input
and output data. The task tracker determines the number of splits depending on the input direction
after obtaining the task setup, and chooses Task Trackers depending on their network proximity to the
data sources. Job Tracker sends a submission to Project Trackers picked.
The Map Phase processing starts where the Mission Tracker collects the input data from the splits. Map
function is invoked by the "InputFormat" that produces key-value pairs in the memory buffer for each record being parsed. The memory buffer is then sorted by invoking the combine function to different nodes of the reducer. Task Tracker notifies the Work Tracker once the map task is complete. The Job Tracker notifies the selected Task Trackers to begin the reduction process once all Task Trackers are completed. Task Tracker reads files from the area and selects the key value pairs for each key. Then the reduction function is invoked which gathers the aggregated values into the output register.
Hadoop Architecture Design: Best Practices
● Use good-quality commodity servers to make it cost-effective and scalable to scale for complex
business cases. For Hadoop architecture one of the best configurations is to start with 6 core
processors, 96 GB of memory and 1 0 4 TB of local hard drives. This is just a decent setup but not
a full one.
● For data processing to be faster and more effective, transfer the processing closely to the data
instead of separating the two.
● Hadoop scales and performs better with local drives so using Only a Bunch of Disks (JBOD) with
replication rather than a redundant array of separate disks (RAID).
● Develop the multi-tenancy Hadoop architecture by sharing the capacity of the computer with
the load scheduler and sharing HDFS storage.
● Do not edit the metadata files as this can corrupt the Hadoop cluster state.
Conclusion:
I hope you reach a conclusion about Hadoop architecture administration. You can learn more about
Hadoop architecture from big data hadoop training